
上一篇是 3 月底写的,这两个月又用 AI 干了几个比较大的项目,攒了一些新感受,继续零散记一下。
1. 这两个月在干啥
DNS业务一个(io_uring支持)、F-Stack 两个(主要是FreeBSD-13.0升级到FreeBSD-15.0)。这两个项目里,已经没有一行代码是手写了。
用的是这几个月比较火的 Spec 驱动 + Harness 工程方式:先让 AI 把文档和知识图谱生成好,再进入实际开发。前期慢一点,后面快得吓人。
2. 效率提升 80%,但代码掌控力会变弱
以前需要忙一两个月的活,现在四五天到一两周就能搞完。如果不算部署上线那些老太太裹脚布的流程,效率提升基本都在80% 以上,而且达到的效果至少能通过我自己的验收。
代价是代码掌控力肯定会弱不少。我现在做的 review 主要就三件:
- Spec 文档
- Plan 工作计划
- 最终的测试结果和验收
代码我也会瞄两眼,但说实话,AI 写的代码有些地方有些技巧是完全没必要的,简单直接、易懂、性能也不差就好。这点 AI 的风格我不是太喜欢,当然这也和一些skill的提示词会有相关性,但是提示词、记忆、规约即使写入了,也是经常被忽略的,没办法。
附带一个意外收获:以前古法编程的时候,文档基本都是事后补、能省则省;现在 Spec 驱动跑下来,详细文档自然就落下了,这部分时间也是白送的。这个效率账我前面那 80% 还没算进去。
3. AI 编程不要并行,老老实实串行
最开始那一两天我是并行干的——这边 AI 跑着代码,那边我顺手处理别的事。看上去事情办了一堆,效率好像翻倍。
但人会非常非常累。
大脑上下文一直在切,一天下来感觉比正常加班还废。强烈不建议这么干,串行就好。 看着像浪费时间,其实更稳。建议可以盯着AI的过程学习或者在AI跑歪时及时打断纠正,或者干点其他不是非常费脑的事情。
4. 35 岁老程序员 vs 年轻人,AI 到底向着谁
最近网上有个声音:AI 对 35+ 老程序员更友好,对应届生不太友好——年轻人少了项目里的实战锻炼,成长断档。
我部分同意。
但年轻人不是完全没机会。串行盯着 AI 干活的时候,可以盯它的分析过程和思考过程。现在 AI 的思考链条已经挺接近人类程序员了——会试错、会回退、此路不通就换条路。年轻人跟着 AI 的思路看,其实是能学到东西的,只是手动调试那种深刻的印象会少一些。
老程序员也一样,借着 AI 的”出声思考”,能很快摸清一个新项目的架构和设计思路。所以年轻人不是没成长路径,只是路径变了,效果可能比传统古法编程要打个折扣。
5. DPDK 程序也能让 AI Agent 自动调试
之前只是内核协议栈的程序使用Agent自动调试,一个小变通就可以让DPDK程序也让Agent自动调试了,不用再自己测试出问题贴给Agent了,用Agent通过ssh自动在client执行命令并回流结果就好了。
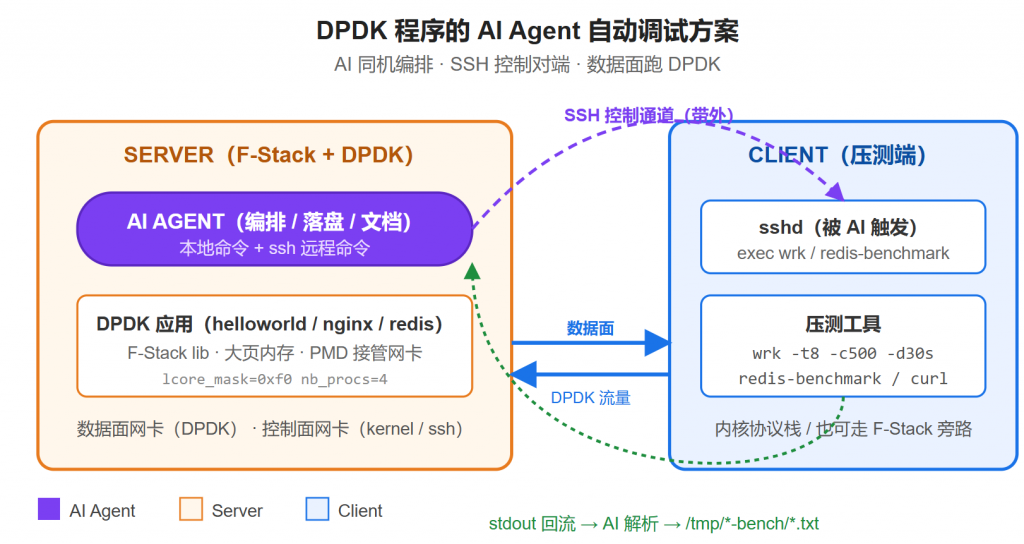
6. 大项目要人工盯着,AI 会跑歪
虽然能自动跑,但大需求我不建议做完全自动化。
原因是 AI 跑长链路任务的时候,会随时蹦出一些需要人工决策的点;更要命的是它会跑歪——一开始走错路,越走越远,最后试错回来虽然能修正,但 token 和时间都白烧了。
人工盯着 AI 干活,看到他思路开始歪了,赶紧终止纠正一下,再让他继续。这个动作很重要,对整个项目的理解也会更深。大项目的”AI + 人工监督”,比”AI 全自动 + 事后验收”靠谱得多。当然这也是我们这种老登的优势😂.
7. 小需求纯自动化基本是噱头
反过来说,那些”AI 7×24 全自动”的小需求演示,说得难听点儿,更多是噱头。
小需求本身就用不了多长时间,纯自动化看起来是省了你那几小时,但你真敢让它合并代码不看一眼?最后还是要人工 review 提交、看测试结果。审核的时间 + 自动跑的时间,跟你串行盯着分步执行的时间比,提升其实非常有限。目前个人对小需求的修改还是有很大一部分是手工改,AI辅助审核的方式。同时建议新人也尽量保留一部分小需求来手写,不要全部丢给AI.
大需求和小需求在自动化收益上的差距非常明显:
- 大需求:80%+ 效率提升,文档白送,但要人工盯
- 小需求:纯自动化看起来酷,但提升不明显,凑合用
8. 这就这样
这两个月最大的体感是:AI 已经能干很多脏活累活,但“让 AI 干”和”让 AI 自己干”是两回事——前者效率提升巨大,后者噱头偏多。
至于会不会取代谁,再过半年看吧。
本文是个人语音口述零散信息后,由 Workbuddy + Claude Code 模拟个人风格整理生成。