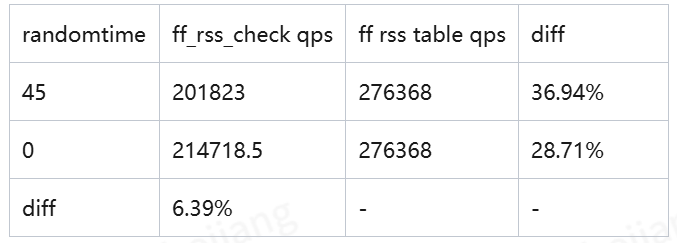
[freebsd.sysctl] net.inet.tcp.delayed_ack=1 # 可以提升大并发的吞吐量 net.inet.tcp.fast_finwait2_recycle=1 net.inet.tcp.finwait2_timeout=5000 net.inet.tcp.maxtcptw=128 # 尽快释放TIME_WAIT状态的端口,增加空闲端口,减少in_pcblookup_local()的调用次数,进而减少ff_rss_check()的调用次数 net.inet.ip.portrange.randomized=1 # Always do random while connect to remote server. # In some scenarios of F-Stack application, the performance can be improved to a certain extent, ablout 5%. net.inet.ip.portrange.randomtime=0 # 对某些特定配置条件下原动态计算ff_rss_check()方式有一定性能提升
IPV6_MTU_DISCOVER 选项不探测是否支持, 强制使用 IPV6_DONTFRAG 选项,该选项目前 FreeBSD 和 Linux 都支持。
编译过程
SSL 库
此处以 OpenSSL quic 为例,可以参考以下方式编译
cd /data/
wget https://github.com/quictls/openssl/archive/refs/tags/OpenSSL_1_1_1v-quic1.tar.gz
tar xzvf OpenSSL_1_1_1v-quic1.tar.gz
cd /data/openssl-OpenSSL_1_1_1v-quic1/
./config enable-tls1_3 no-shared --prefix=/usr/local/OpenSSL_1_1_1v-quic1
make
make install_sw
cd /data/f-stack/adapter/sysctall make clean;make all ls -lrt fstack libff_syscall.so helloworld_stack helloworld_stack_thread_socket helloworld_stack_epoll helloworld_stack_epoll_thread_socket helloworld_stack_epoll_kernel
export FF_PATH=/data/f-stack export PKG_CONFIG_PATH=/usr/lib64/pkgconfig:/usr/local/lib64/pkgconfig:/usr/lib/pkgconfig cd /data/f-stack/adapter/sysctall export FF_KERNEL_EVENT=1 export FF_MULTI_SC=1 make clean;make all
ip link add link eth0 name eth0.10 type vlan id 10 ifconfig eth0.10 10.10.10.10 netmask 255.255.255.0 broadcast 10.10.10.255 up route add -net 10.10.10.0/24 gw 10.10.10.1 dev eth0.10 ip link add link eth0 name eth0.20 type vlan id 20 ifconfig eth0.20 10.10.20.20 netmask 255.255.255.0 broadcast 10.10.20.255 up route add -net 10.10.20.0/24 gw 10.10.20.1 dev eth0.20 ip link add link eth0 name eth0.30 type vlan id 30 ifconfig eth0.30 10.10.30.30 netmask 255.255.255.0 broadcast 10.10.30.255 up route add -net 10.10.30.0/24 gw 10.10.30.1 dev eth0.30 # 设置各 vlan 的外网 VIP ifconfig lo.0 110.110.110.110 netmask 255.255.255.255 ifconfig lo.1 120.120.120.120 netmask 255.255.255.255 ifconfig lo.2 130.130.130.130 netmask 255.255.255.255
设置策略路由
echo "10 t0" >> /etc/iproute2/rt_tables echo "20 t1" >> /etc/iproute2/rt_tables echo "30 t2" >> /etc/iproute2/rt_tables # 设置各 vlan 的路由表, 并设置对应的网关地址 ip route add default dev eth0.10 via 10.10.10.1 table 10 ip route add default dev eth0.20 via 10.10.20.1 table 20 ip route add default dev eth0.30 via 10.10.30.1 table 30 #systemctl restart network # 从对应 VIP 出去的包使用对应 vlan 的路由表 ip rule add from 110.110.110.0/24 table 10 ip rule add from 120.120.120.0/24 table 20 ip rule add from 130.130.130.0/24 table 30
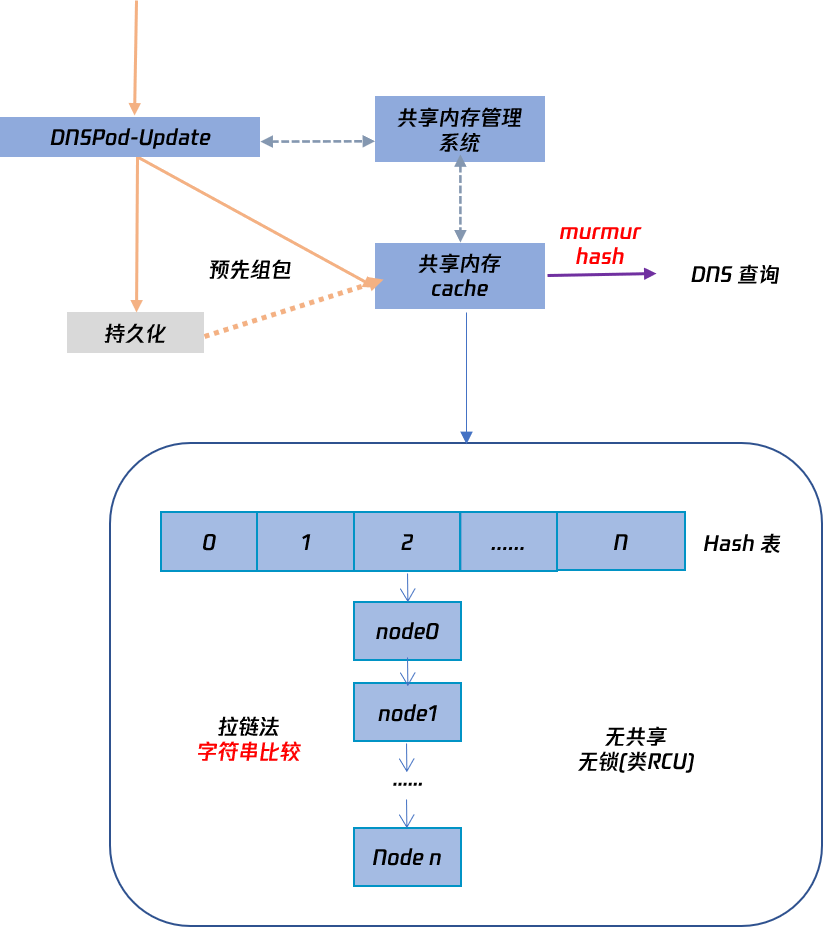
提供接口ff_zc_mbuf_get(),用于应用提前申请包含可以由内核直接使用的mbuf的结构体作为应用层数据缓存,接口声明如下。int ff_zc_mbuf_get(struct ff_zc_mbuf *m, int len);该接口输入struct ff_zc_mbuf *指针和需要申请的缓存总长度,内部将通过m_getm2()分配mbuf链,首地址保存在ff_zc_mbuf结构的bsd_mbuf变量中,后续可以传递给ff_write()接口。其中m_getm2()为标准socket接口拷贝应用层数据到协议栈时分配mbuf链的接口,所以使用该接口范围的mbuf链作为应用层缓存,可以在发送数据时完全兼容。
提供了缓存数据写入函数ff_zc_mbuf_write(),函数声明如下,
int ff_zc_mbuf_write(struct ff_zc_mbuf *m, const char *data, int len); 应用层在保存待发送的数据时,应通过接口ff_zc_mbuf_wirte()直接将数据写到ff_zc_mbuf指向的mbuf链的缓存中,ff_zc_mbuf_wirte()接口可以多次调用写入缓存数据,接口内部自动处理缓存的偏移情况,但多次总的写入长度不能超过初始申请的缓存长度。
应用调用ff_write()接口时指定传递ff_zc_mubf.bsd_mbuf为buf参数,示例如下所示,ff_write(clientfd, zc_buf.bsd_mbuf, buf_len);在m_uiotombuf()函数中,直接使用传递的mbuf链的首地址,不再额外进行mbuf链的分配和数据拷贝,如下所示,#ifdef FSTACK_ZC_SEND if (uio->uio_segflg == UIO_SYSSPACE && uio->uio_rw == UIO_WRITE) { m = (struct mbuf *)uio->uio_iov->iov_base; /* 直接使用应用层的mbuf链首地址 */ uio->uio_iov->iov_base = (char *)(uio->uio_iov->iov_base) + total; uio->uio_iov->iov_len = 0; uio->uio_resid = 0; uio->uio_offset = total; progress = total; } else { #endif m = m_getm2(NULL, max(total + align, 1), how, MT_DATA, flags); /* 拷贝模式分配mbuf链*/ if (m == NULL) return (NULL); m->m_data += align; /* Fill all mbufs with uio data and update header information. */ for (mb = m; mb != NULL; mb = mb->m_next) { length = min(M_TRAILINGSPACE(mb), total – progress); error = uiomove(mtod(mb, void *), length, uio); /* 拷贝模式拷贝应用层数据到协议栈 */ if (error) { m_freem(m); return (NULL); } mb->m_len = length; progress += length; if (flags & M_PKTHDR) m->m_pkthdr.len += length; } #ifdef FSTACK_ZC_SEND } #endif
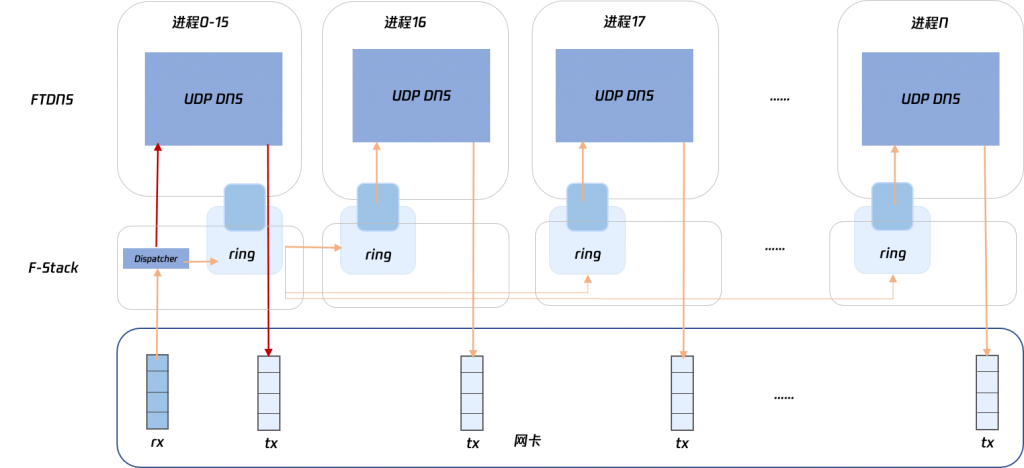
既然网卡开启 16 个接收队列时可以达到最好的接收性能,那么很自然的一个想法,将业务程序的架构由 Run to completion 改为 Pipeline 架构,只开启 16 个接收队列专门用于接收 DNS 请求,再通过 rte ring 将请求报转发到其他业务进程进行实际的 DNS 解析后再直接发送出去,虽然单进程性能会因为 CPU cache miss 的问题急剧下降,但是可以使用更多的 CPU 运行业务进程来弥补,架构简图如下所示。
Pipeline 架构 【注】红色箭头为与 RTC 架构的数据包流向的区别
F-Stack 本身已经提供了函数 ff_regist_packet_dispatcher() 用于对接收到的数据包进行重新分发,且 FTDNS 中已经使用来直接进行 UDP DNS 的解析,稍作修改前 16 个进程仅分发,不再处理 DNS 解析即可,但是实际测试发现转发性能太差,perf 分析主要是软分发回调函数是对数据包一个个进行处理的,性能较差。
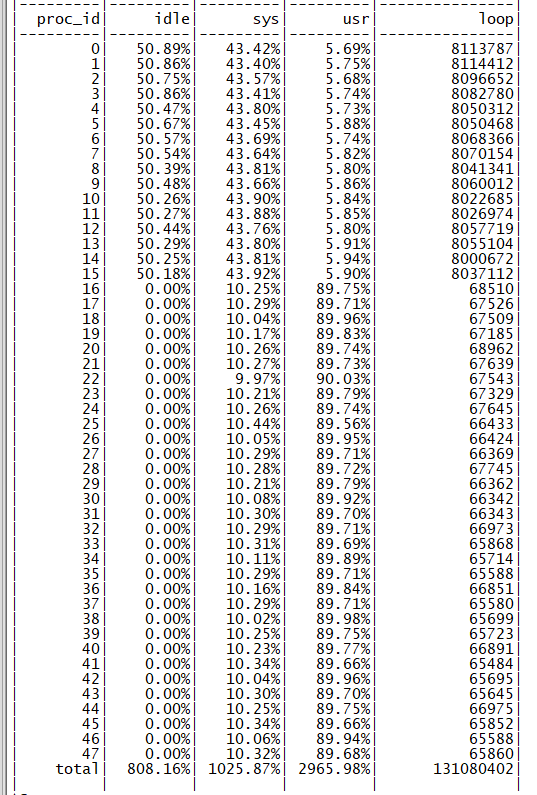
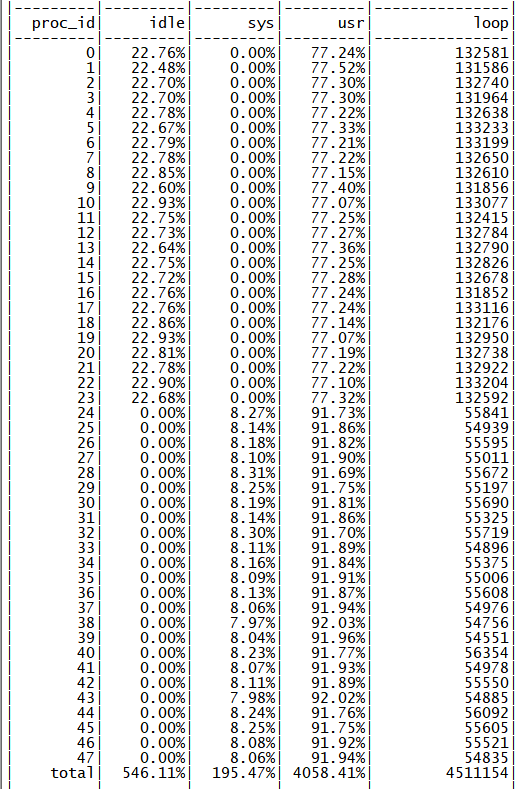
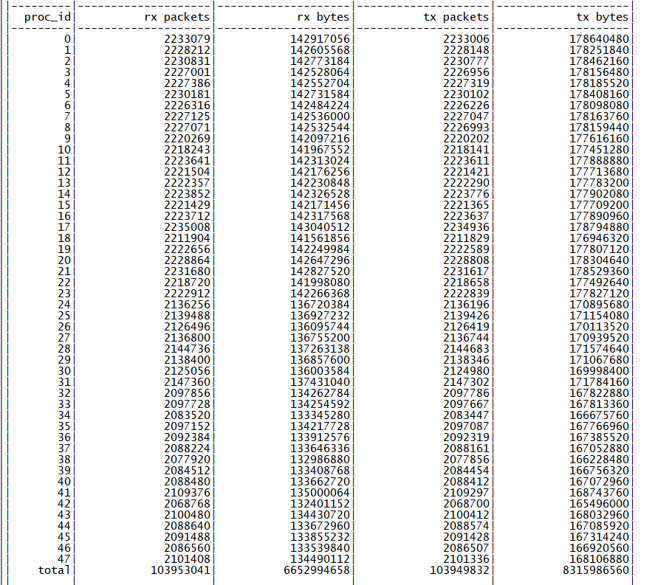
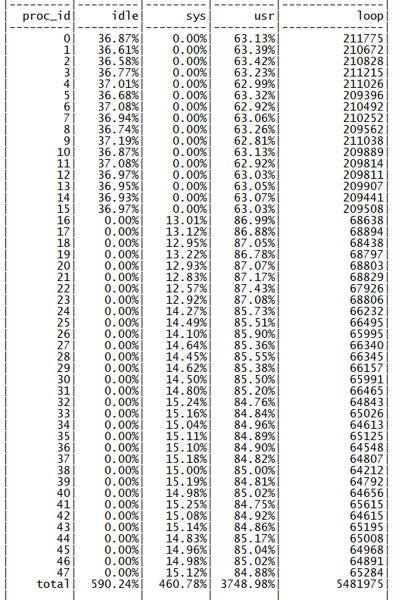
此时 48 核为同一个 NUMA 节点的物理核心,全部使用后性能可以达到 68M QPS,单核性能下降约 12%,符合前期的心里预期,查看 perf 信息,热点也符合预期(如下图所示)。
跨 CPU 访问数据热点
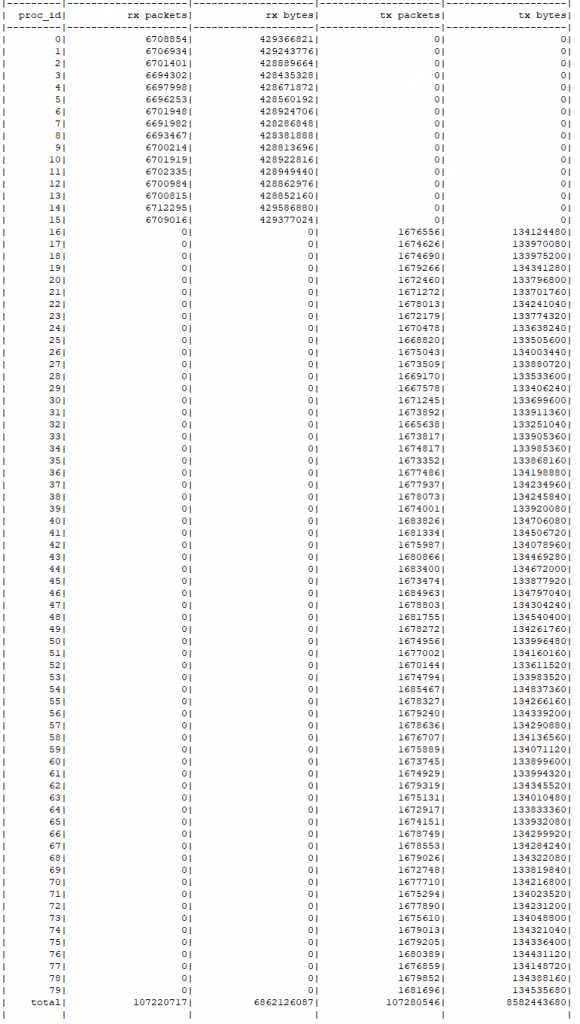
如果有更多业务进程,是否就可以达到小目标了呢?因为机器架构限制的原因,本物理核的另外 48 个超线程核心很难使用到,且根据历史经验,即使使用性能提升也非常小,所以直接继续使用另一个 NUMA 节点的 CPU 的物理核心进行进一步测试,可以用到 80 个 CPU 核心,对应的收包分发线程调整为 20 进程,测试得到 Pipeline 的最优性能如下图所示。