本文主要介绍递归DNS的SRTT本身机制及如何进行更进一步的优化,来达到更好的递归效果。都是字,不想弄图、表和数字,格式也有点乱,不想整理了,凑合看吧
1. SRTT本身机制
本节仅对SRTT进行简单的介绍供了解,不进行特别深入和详细的分析。
SRTT(Smoothed Round-Trip Time,平滑往返时延)是在递归DNS系统里,用加权平均算法计算出的上游DNS服务器的“响应时延”估值,它用于优化解析性能和选择最快的上游服务器。
延伸阅读
BIND的SRTT机制总体做的还是相对比较好的,可以参考 https://developer.aliyun.com/article/622410。
而Unbound社区版的SRTT做的则不够好,基本就是可用权威IP完全随机,递归的平均延迟非常高,所以在实际业务使用前必须进行优化,具体算法优化可以参考相关论文或BIND的实现等。
虽说递归DNS选择权威服务器时都希望选择延迟更低,但在最大限度降低递归时延的前提下,也要遵循一定的规则,如
- 需要有一定的随机性选择非延迟最低的权威IP来自适应权威IP的RTT的波动和服务器的突然故障。
- 如某个权威IP正常RTT很低,但偶发丢包被惩罚延迟后,需要能够逐步平滑降低其RTT。
- 如果低RTT的权威IP突然故障,除了丢包惩罚延迟外,还需要随机性来选择其他权威DNS IP,防止单个IP不可用导致整个域名解析异常。
- 标记不可用的IP也需要定时发送DNS请求。
- 不可用的IP恢复可用后需要使用该机制探活标记为恢复可用
- BIND和UNBOUND都会在15或30分钟完全重置一次权威IP的相关状态,其中包括RTT,以及IP的EDNS支持状态等。
- 也可以低频率的对惩罚到标记不可用的IP做并发异步的DNS探活请求。
- 不能向单一权威IP发送过于集中的请求,降低被权威封禁递归IP的概率。
- 一个可探讨的方案介绍:如果本次不进行随机选择递归IP,选择最低RTT的IP时候再进行二次选择,1/2直接选择最低RTT的权威服务器,1/2在最低RTT差距一定范围内(如minrtt + 20ms,也认为有比较低的延迟)的其他权威服务器IP中随机选择。
- 国内的各大权威DNS服务商的服务只要不是真实的攻击,常规的SRTT优化很是很难触发递归IP被封禁的场景的,但是一些单位、机构等自建的权威DNS,如果单个IP请求量较大则比较容易触发,所以这里也是递归DNS必须要考虑的一种场景。
2. SRTT的配套机制优化
只有SRTT本身的选择机制对一个递归DNS是不够的,还必须配合多个其他配套系统来使用,而这些配套系统对递归DNS的整体递归时延也是非常重要的。
2.1 某个权威DNS IP的SRTT生效范围
在实际业务中,存在以下两种场景会使多个域名使用相同的权威DNS IP
- 不同的域名会使用相同的NameServer(NS)
- 不同的域名使用的NS不同,但NS对应的IP相同(如腾讯云解析/DNSPod提供的个性化NS功能)
在我们的常规认知中,既然权威DNS IP相同,那么统一进行SRTT的探测和选择即可,这样多个域名的平均递归延迟都可以有效降低,如在每次权威IP状态重置后快速重新探测到RTT最低的权威DNS IP,且对所有域名生效。
但现实是相反的,多数递归DNS对这种场景的权威DNS IP探测是域名相关的,不同域名的权威DNS IP即使相同,也是分别独立探测和存储状态的(如Unbound的)。
对于某些特殊场景,这种做法可能有一定用处,如同一个IP对域名A支持EDNS,对域名B不支持等,但这极大增加了递归DNS解析时延(也浪费了一些内存,虽然现代服务器不怎么在意了)。
目前腾讯云/DNSPod的递归服务器的做法是所有域名只要权威DNS IP相同即共享一份SRTT的探测和选择结果,可以大幅提高选择RTT低的权威DNS概率(尤其是请求量不大的域名),降低解析延迟,不考虑一些特别极端的场景(也可以解析,但可能不是最优的结果,且此类极端场景在国内的权威DNS服务商中基本不存在)。
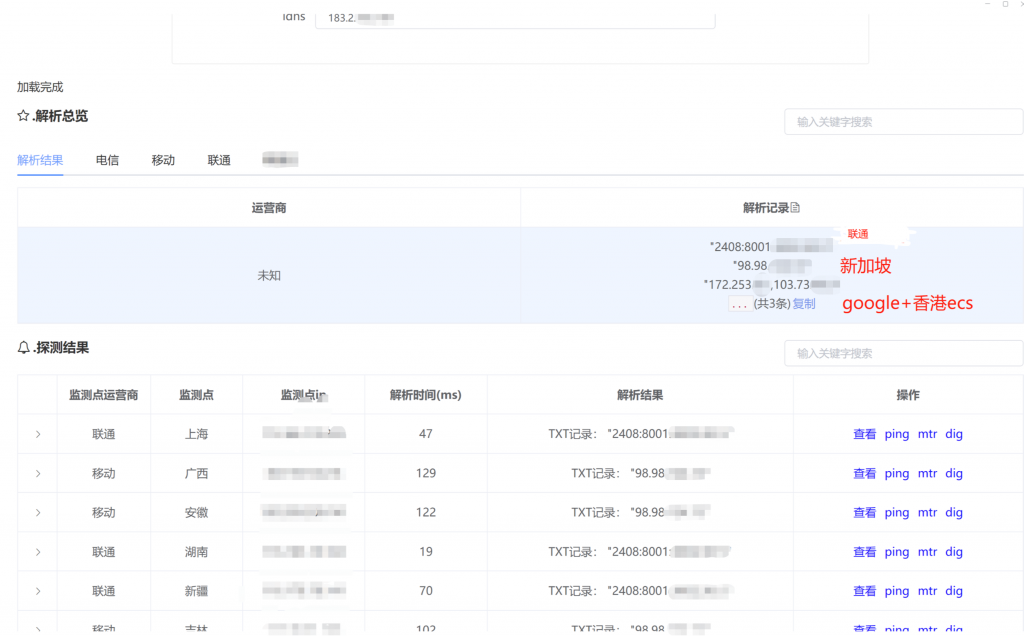
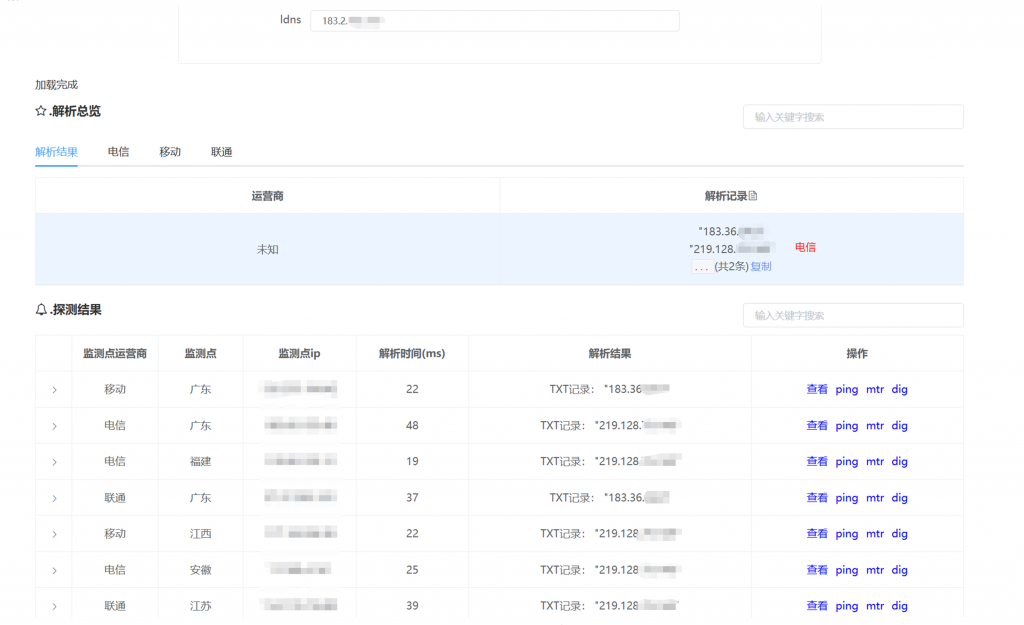
2.2 权威DNS IP的GEO优化
大家都知道普通域名的DNS解析可以做智能解析(分线路、GEO、基于延迟等),来给不同地域不同运营商的客户端分配不同的解析结果,达到降低延迟或节省成本的目的。那么对于给递归DNS使用的NameServer(NS)域名是否可以使用智能解析,来达到同样的目的呢?毕竟因为各种原因,国内大部分权威DNS服务商很难完全使用完全相同的Anycast IP在全球同时提供很高的高可用和很低的延迟,如果该方案可行,则权威DNS服务商有了一个变通的方式来同时满足高可用和低延迟的需求,如除了Anycast IP外还可以在不通地区提供一些本地的Unicast IP来降低本地递归DNS的访问延迟,比如目前腾讯解析/DNSPod和阿里云解析都做了该操作,那么效果如何呢。
答案是一半一半。
递归获取一个域名的权威DNS的NS IP有两个渠道,胶水记录和权威服务器的记录,其中NS域名在注册商/局设置胶水记录不支持智能解析,而在其本身权威DNS设置的解析记录则是可以支持设置智能解析线路的,下面分别进行介绍。
2.2.1 注册局的TLD服务器返回的glue record
- 胶水记录(Glue Record)是一种特殊的DNS记录,用于解决域名解析过程中的循环依赖问题。当域名的权威DNS服务器(NS记录)是当前域名的子域名时,胶水记录是必须存在的(如后续示例所示),由域名所有者直接在注册商/局(父域DNS,如.com的TLD服务器)中提供子域名服务器的IP地址,确保递归DNS能够正确找到目标的权威DNS服务器。
dig @a.gtld-servers.net ns3.dnsv5.com
; <<>> DiG 9.11.26-RedHat-9.11.26-6.tl3 <<>> @a.gtld-servers.net ns3.dnsv5.com
; (2 servers found)
;; global options: +cmd
;; Got answer:
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 45009
;; flags: qr rd; QUERY: 1, ANSWER: 0, AUTHORITY: 2, ADDITIONAL: 11
;; WARNING: recursion requested but not available
;; OPT PSEUDOSECTION:
; EDNS: version: 0, flags:; udp: 4096
;; QUESTION SECTION:
;ns3.dnsv5.com. IN A
;; AUTHORITY SECTION:
dnsv5.com. 172800 IN NS ns3.dnsv5.com.
dnsv5.com. 172800 IN NS ns4.dnsv5.net.
# 因为NS域名ns3.dnsv5.com是请求域名dnsv5.com的子域名,此时胶水几率是必须返回的,否则后续继续向TLD服务器请求ns3.dnsv5.com还是返回上面两条NS记录,造成死循环
# 只返回tld相同的ns3.dnsv5.com的胶水记录,而不返回ns4.dnsv5.net的胶水记录
;; ADDITIONAL SECTION:
ns3.dnsv5.com. 172800 IN A 1.12.0.17
ns3.dnsv5.com. 172800 IN A 1.12.0.18
ns3.dnsv5.com. 172800 IN A 1.12.14.17
ns3.dnsv5.com. 172800 IN A 1.12.14.18
ns3.dnsv5.com. 172800 IN A 101.227.168.52
ns3.dnsv5.com. 172800 IN A 108.136.87.44
ns3.dnsv5.com. 172800 IN A 163.177.5.75
ns3.dnsv5.com. 172800 IN A 220.196.136.52
ns3.dnsv5.com. 172800 IN AAAA 2402:4e00:1470:2::f
ns3.dnsv5.com. 172800 IN A 35.165.107.227
;; Query time: 217 msec
;; SERVER: 192.5.6.30#53(192.5.6.30)
;; WHEN: Fri Aug 15 15:59:20 CST 2025
;; MSG SIZE rcvd: 255- TLD服务器一般只有请求的域名的TLD和本域名设置的NS的TLD一致,会返回胶水记录的(这里大部分其实是非必须的,但是同时返回了胶水记录可以减少一次额外的请求,降低延迟),否则一般不返回胶水记录。如example.com设置NS为ns1.example.com, ns2.example.net, 那么这时候向TLD服务器请求example.com的时候,TLD服务器就会返回example.com的NS记录ns1.example.com和ns2.example.net,且同时返回ns1.example.com的A和AAAA记录(TLD相同,都是.com),但并不会返回ns2.example.net的胶水记录(TLD不同, .com vs .net),如上述和下述请求所示
dig @a.gtld-servers.net dnsov.net
; <<>> DiG 9.11.26-RedHat-9.11.26-6.tl3 <<>> @a.gtld-servers.net dnsov.net
; (2 servers found)
;; global options: +cmd
;; Got answer:
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 8363
;; flags: qr rd; QUERY: 1, ANSWER: 0, AUTHORITY: 2, ADDITIONAL: 11
;; WARNING: recursion requested but not available
;; OPT PSEUDOSECTION:
; EDNS: version: 0, flags:; udp: 4096
;; QUESTION SECTION:
;dnsov.net. IN A
;; AUTHORITY SECTION:
dnsov.net. 172800 IN NS ns3.dnsv5.com.
dnsov.net. 172800 IN NS ns4.dnsv5.net.
# 只返回tld相同的ns4.dnsv5.net的胶水记录,而不返回ns3.dnsv5.com的胶水记录,但其实这里的胶水记录并不是必须要返回的,因为dnsov.net和dnsv5.net是两个不同的域名,再次请求并不会造成死循环,但是同时返回了胶水记录可以减少一次额外的请求,降低延迟
;; ADDITIONAL SECTION:
ns4.dnsv5.net. 172800 IN A 1.12.0.16
ns4.dnsv5.net. 172800 IN A 1.12.0.19
ns4.dnsv5.net. 172800 IN A 1.12.14.16
ns4.dnsv5.net. 172800 IN A 1.12.14.19
ns4.dnsv5.net. 172800 IN A 112.80.181.106
ns4.dnsv5.net. 172800 IN A 117.135.128.152
ns4.dnsv5.net. 172800 IN A 124.64.205.152
ns4.dnsv5.net. 172800 IN A 13.37.58.163
ns4.dnsv5.net. 172800 IN AAAA 2402:4e00:111:fff::8
ns4.dnsv5.net. 172800 IN A 49.7.107.152
;; Query time: 192 msec
;; SERVER: 192.5.6.30#53(192.5.6.30)
;; WHEN: Fri Aug 15 16:00:30 CST 2025
;; MSG SIZE rcvd: 261- 这里未介绍子域名授权场景的胶水记录,总体原则是一致的。
2.2.2 NS域名本身权威服务器返回的IP记录
NS域名(如ns3.dnsv5.com)在其权威DNS(如腾讯云解析/DNSPod)设置解析记录的时候,和普通域名可以一样设置智能解析(如境内设置一批IP,境外设置另一批IP等),和普通域名的使用没有区别。
2.2.3 递归DNS的行为及优化
递归DNS在进行迭代查询时,有可能从TLD服务器直接获取到NS域名的胶水记录,也可能从权威DNS获取,且两处获取的记录可能不同(部分检测系统会告警,但忽略即可),而权威DNS设置的IP支持智能解析,提供了更大的优化空间,一般相比胶水记录是更好的选择(且非专业技术人员常常忽视对胶水记录的维护),那递归DNS如何使用和优化呢。
常规的递归DNS(如BIND和UNBOUND)一般是这种行为(会略有不同,总体行为类似)
- 如果向TLD服务器请求某个域名时,TLD服务器同时返回了NS的胶水记录,那么直接使用胶水记录作为NS的IP,不会再去向NS的权威请求记录
- 如果向TLD服务器请求某个域名时,TLD服务器没有返回NS的胶水记录,则再去正常查询NS域名的记录时,可能回会权威请求NS记录,获取到权威可能设置的分线路智能解析结果,从而后续优先使用权威返回的解析记录
- 有用户向递归DNS显示请求NS域名的A/AAAA记录,那么递归DNS必然会向NS域名的权威请求一次NS的A/AAAA记录(胶水记录不是其域名权威返回的,用户显式的请求去需要去获取权威设置的记录,而不能直接返回缓存的胶水记录),获取到权威可能设置的分线路智能解析结果,从而后续优先使用权威返回的解析记录
- 如果权威返回的解析记录全部不可用,则重新回退到使用胶水记录提升可用性
可以看出来,常规的递归DNS不会主动去获取权威DNS的分线路智能解析结果,只会在被动获取到权威返回结果的时候,代替胶水记录进行优先使用,从腾讯云解析/DNSPod使用的实际效果看,权威解析才会设置的解析IP的流量比例总体并不低,这样设置还是有比较好的效果的(具体数据就不提供了)。
那对递归DNS能不能更进一步的进行优化呢,当然可以
- 即使递归DNS从TLD服务器获取到了NS域名的胶水记录,在正常向胶水记录IP发起查询请求的同时,也自动异步去解析NS域名在权威的A/AAAA记录, 使用NS权威解析记录的比例可以大幅提高。
- 根域名、TLD域名以及海外大厂的NS等域名不必做这个操作,因为记录一般都是一致的Anycast IP
- 腾讯云/DNSPod所有对外提供服务的公共DNS、HTTPDNS、DoH、DoT、云内网DNS等的后端递归DNS都支持该项优化