
腾讯云 DNSPod 的权威 DNS 解析目前包含两个版本,基于 F-Stack 的 FTDNS 和基于内核协议栈的 DPDNS,其中 FTDNS 目前性能远高于 DPDNS,是腾讯云对外提供权威 DNS 服务的主力,而 DPDNS 目前主要用作异构容灾及部分特殊场景的部署,如部分只能使用 CVM 或私有化部署的场景。
本文主要介绍 FTDNS 在对 100G 机型进行适配优化的过程,UDP DNS 如何达到单机 1 亿 QPS 的性能,主要涉及网络 I/O 的性能优化和 DNS 解析计算资源的平衡分配,对于 TCP DNS 和内核版的 DPDNS 的性能优化后续将专门进行介绍。
测试平台
测试程序:FTDNS,权威DNS解析程序
F-Stack: 1.21(DPDK 19.11)
OS: Tencent tlinux release 2.2 (Final)
Kernel: 4.14.105-1-tlinux3-0020
CPU: AMD EPYC 7K62 48-Core Processor * 2
NIC: Mellanox Technologies MT28800 Family [ConnectX-5 Ex]
Device type: ConnectX5
Name: MCX516A-CDA_Ax_Bx
Description: ConnectX-5 Ex EN network interface card; 100GbE dual-port QSFP28; PCIe4.0 x16; tall bracket; ROHS R6
Run to completion 架构
因为 DNS 解析的总体逻辑相对比较简单,除了网络 I/O 外只有查找本地缓存查找,所以 FTDNS 在常规架构下完全使用 RTC(Run to completion) 架构以达到更好的性能,网卡收发队列、协议栈、应用与 CPU 核心一一绑定,如下图所示

【注】简化结构,仅简单示意 UDP DNS
对于 UDP DNS 请求,直接通过网卡的 RSS 功能将请求包负载收包至已经绑定到各个队列和 CPU 的 FTDNS 业务进程中,并且使用 F-Stack lib 提供的 ff_regist_packet_dispatcher() 函数直接注册回调函数对 UDP 的 DNS 请求包直接进行应用层的解析处理,并直接回包,旁路掉同为用户态的 FreeBSD 的网络协议栈。
性能测试
在拿到 100G 的机器后,使用原有程序直接进行了性能测试,最优性能表现如下图所示


该测试机型单个 NUMA 节点的 CPU 为 48 核 96 线程 ,对应一张 100G 网卡,为了达到最优性能,正常只使用 48 个物理核进行测试,通过对不同核数分别进行测试,发现在使用 32 核左右时才能达到最优性能,但是也只有 76M 的 QPS,离一亿的小目标差距有点大,接下来进行瓶颈分析。
瓶颈分析
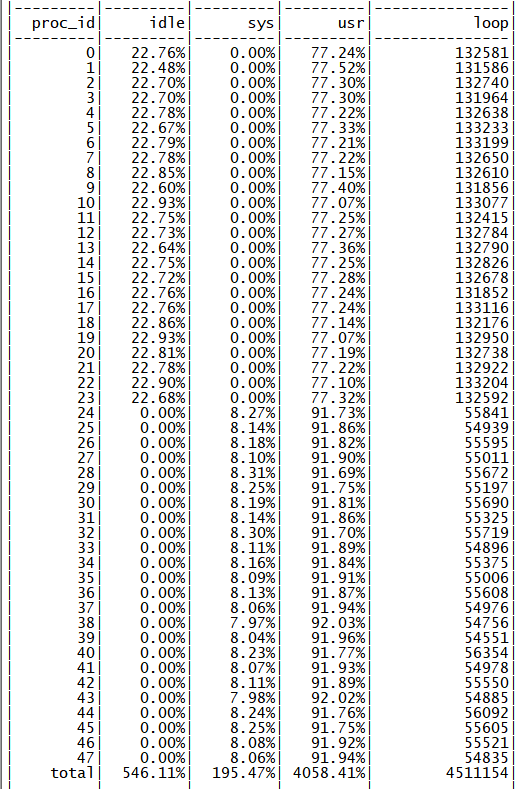
因为直接启动 48 个业务进程测得的性能很低,只有 35M QPS 左右,而此时 CPU 并没跑满,空闲都在一半以上,如下图所示


所以分别启动不同数量的业务进程分别测得性能数据,且为了排除 FTDNS 业务应用本身性能的影响,同时做了部分关闭 DNS 实际解析逻辑(其他处理逻辑保留)的 echo server 的对比测试,测试结果大致如下
| 进程数 | 空载性能(QPS) | DNS性能(QPS) |
| 4 | 80 M | / |
| 8 | 107 M | 19 M |
| 12 | 113 M | 28 M |
| 16 | 113 M | 38 M |
| 20 | 84 M | 47 M |
| 24 | 80 M | 56 M |
| 32 | 77 M | 76 M |
| 40 | 40 M | 40 M |
| 48 | 37 M | / |
很明显,从以上数据可以得出几个结论:
- 收发包性能受队列数影响很大:当队列数较少时,收发包性能主要受 CPU 性能本身影响;当接近 16 个队列时,收发包性能最优,可以达到 113M QPS(非单纯收发的最高性能,因为还包括其他处理逻辑),之后性能急剧下降,分析主要是受 PCIE 通道数量为 16 个的影响,当队列数超过 16 后造成性能下降(此条以后如拿到其他配置机型后可做对比测试进行验证)。
- DNS 解析查询性能可线性扩展:当进程数较少时,FTDNS 的性能主要受限于 CPU 的计算性能,在达到收发包极限前,性能可以随进程数增长而线性增长(纯内存缓存、无共享、无锁等),超过 32 进程之后则受收发包性能影响,CPU 出现大量空闲。
优化方向
1. 调整网卡相关参数
通过查看 MLX5 网卡的相关参数文档,对部分参数进行组合调整并压测验证,如 mprq_en, rxqs_min_mprq, mprq_log_stride_size, mprq_max_memcpy_len, txqs_min_inline, txq_mpw_en 等,期望可以达到在网卡开启更多接收队列(如 48 个)也能达到更高的收发包性能,最终通过大量的测试表明,在48队列时网卡的收发包性能依然很低,辅证是由 PCIE 通道数引起的性能下降,此处不再详细展开。
2. 架构优化
2.1 Pipeline
既然网卡开启 16 个接收队列时可以达到最好的接收性能,那么很自然的一个想法,将业务程序的架构由 Run to completion 改为 Pipeline 架构,只开启 16 个接收队列专门用于接收 DNS 请求,再通过 rte ring 将请求报转发到其他业务进程进行实际的 DNS 解析后再直接发送出去,虽然单进程性能会因为 CPU cache miss 的问题急剧下降,但是可以使用更多的 CPU 运行业务进程来弥补,架构简图如下所示。

【注】红色箭头为与 RTC 架构的数据包流向的区别
F-Stack 本身已经提供了函数 ff_regist_packet_dispatcher() 用于对接收到的数据包进行重新分发,且 FTDNS 中已经使用来直接进行 UDP DNS 的解析,稍作修改前 16 个进程仅分发,不再处理 DNS 解析即可,但是实际测试发现转发性能太差,perf 分析主要是软分发回调函数是对数据包一个个进行处理的,性能较差。
所以不得不侵入式修改 F-Stack 的转发逻辑,在 F-Stack 的收发包主循环中,
前 16 个进程 在接收到数据包后直接批量根据配置转发到业务进程中,转发到 ring 的性能得到提升,但业务进程单核性能也下降明显,实测结果如下图所示,

【注】该统计将 F-Stack 对流量信息统计进行了修改,软分发也统计到了 worker 进程上,更直观
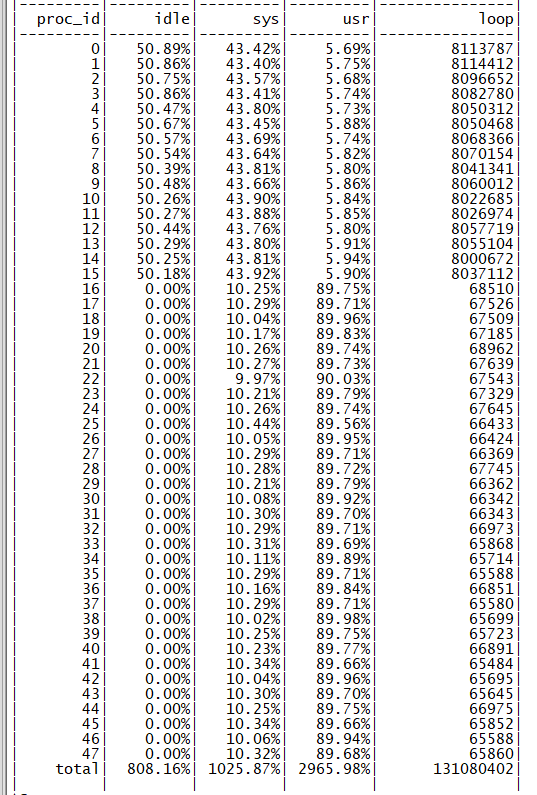
48 进程 Pipelie CPU
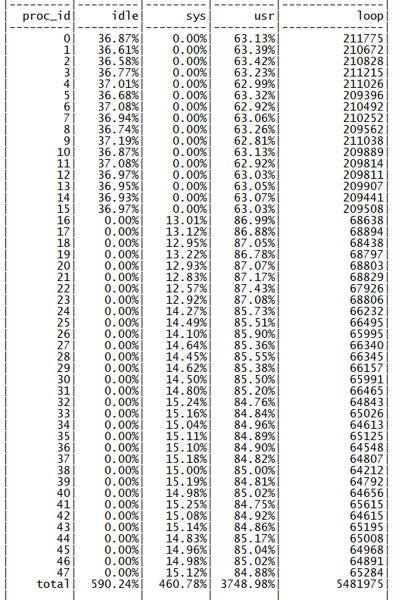
此时 48 核为同一个 NUMA 节点的物理核心,全部使用后性能可以达到 68M QPS,单核性能下降约 12%,符合前期的心里预期,查看 perf 信息,热点也符合预期(如下图所示)。

如果有更多业务进程,是否就可以达到小目标了呢?因为机器架构限制的原因,本物理核的另外 48 个超线程核心很难使用到,且根据历史经验,即使使用性能提升也非常小,所以直接继续使用另一个 NUMA 节点的 CPU 的物理核心进行进一步测试,可以用到 80 个 CPU 核心,对应的收包分发线程调整为 20 进程,测试得到 Pipeline 的最优性能如下图所示。

【注】:此处 PPS 统计使用的是 F-Stack 原始统计方式,不够直观

性能有很大进展,已经达到了 95M QPS,离小目标不远了,但是也可以看出来进程 48 – 79 跨 NUMA 访问的 32 个进程 CPU 使用率是高于本 NUMA 节点的 CPU 的,查看 perf 信息同样证明了跨 NUMA 访问存在的问题。
此架构下继续调整尝试多次,包括继续增加 CPU 等,也无法达到更好的性能,只好尝试其他方向。
2.2 Run to completion + Pipeline
分析 48 进程 Pipeline 架构的 CPU 图可以发现,dispatcher 进程的 CPU 尚有一半空闲,是否也可以利用起来呢?
继续对分发部分代码进行稍微的修改, dispatcher 进程可以支持按照配置的分发进程数自动将收包分别交由本进程的应用层进行解析处理或者通过 Ring 转发到其他 worker 进程,架构如下图所示
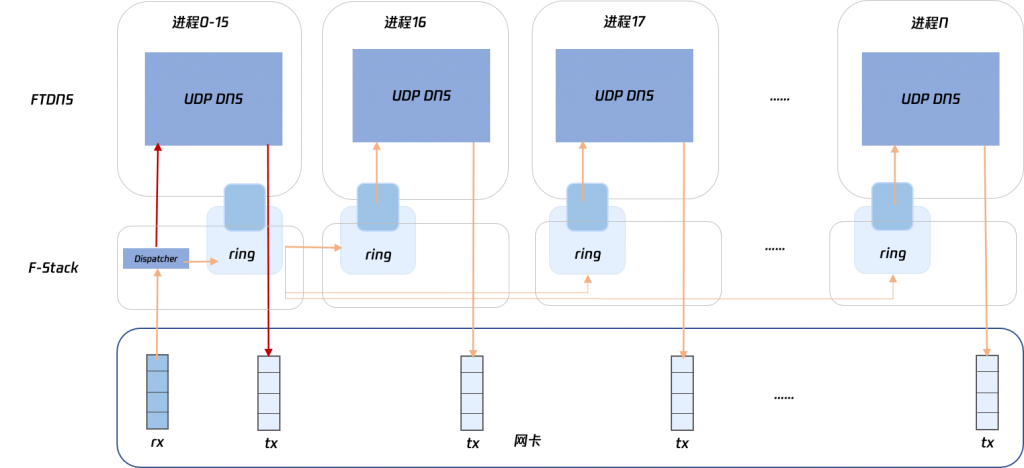
【注】:红色箭头表示与 Pipeline 架构不同的数据包流向
经过多次尝试调整不同进程的数量以及数据包分发比例,最终还是每个 dispatcher 与 worker 进程处理相同量的数据包,但是一个 dispatcher 进程可以根据配置自动对应多个 worker 进程,并测试得到了此时的最优性能,如下图所示

此处达到了 92M的性能,但是总性能还是略差于 Pipleline 性能,优势就是只使用了 48 个 CPU,使用 24 dispatcher + 24 worker 与 16 dispatcher + 32 worker 总体性能相当,此时虽然 dispatcher 进程依然有部分 CPU 空闲,但是增加其 DNS 处理比列并不能提升整体性能了,主要是因为如果分配更多的 CPU 时间片到 DNS 业务处理,则整体轮询次数减少,导致收包能力下降。
此时但是小目标依然没能实现,还需要考虑其他优化点。
2.3 单进程性能提升
在 RTC 测试中,单核 DNS 的性能虽然达到 2.38M QPS,已经很高了,但是通过 perf 分析在 DNS 业务处理逻辑中查询缓存时的 Hash 和 Key 的字符串比较函数占用 CPU 较高,依然有一定的优化空间,先看下 FTDNS 内存缓存结构,如下图所示
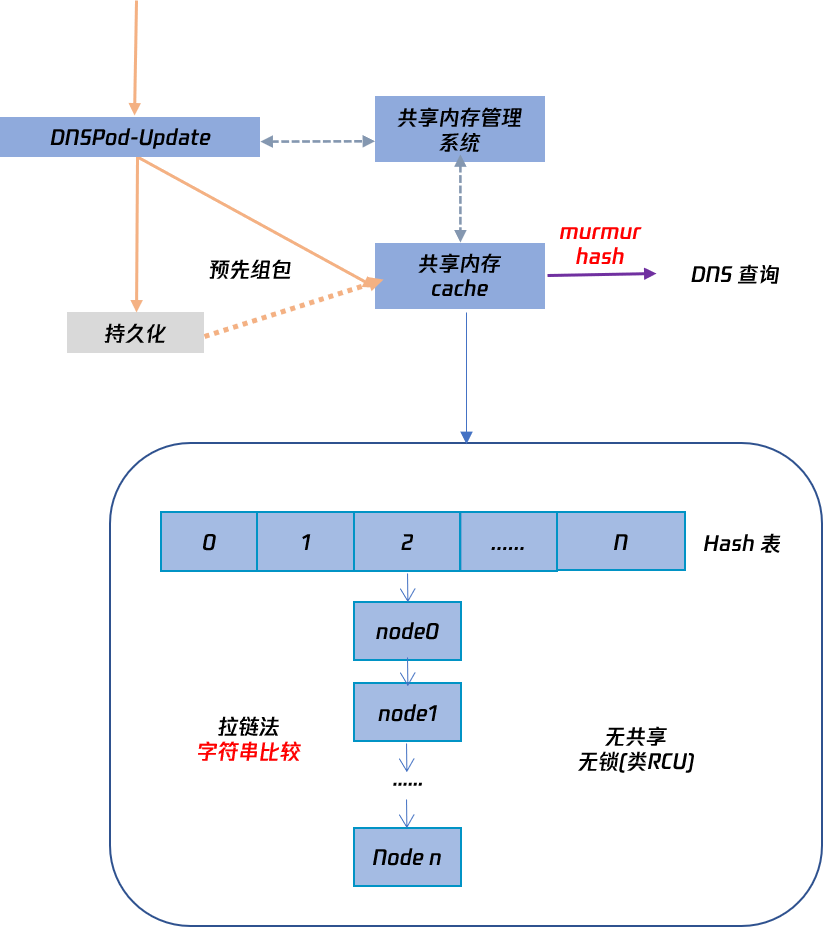
内存缓存是常规的 Hash 表结构,解决 Hash 冲突使用的是拉链法,存储的是写入时已经组好 DNS 应答包格式的数据,且无共享(无任何多写的数据结构)、无锁(类似 RCU 锁思想,但是并不加锁)等。
对 Hash 的 Key 进行优化,去除了部分不必包含和字符串比较函数进行优化,去除了部分非必要的字段,减少了需要进行 Hash 计算的 Key 长度。
因为大部分 Key 较短,暂未使用 memcmp() 进行比较, 因为仅需要判断 Key 是否相等即可,所以自行实现字符串比较函数,去除标准比较函数中多余的操作。
优化完成后,Pipeline 和 RTC + Pipeline 架构的性能都达到了 1 亿(100M) QPS 的小目标,性能测试结果如下所示
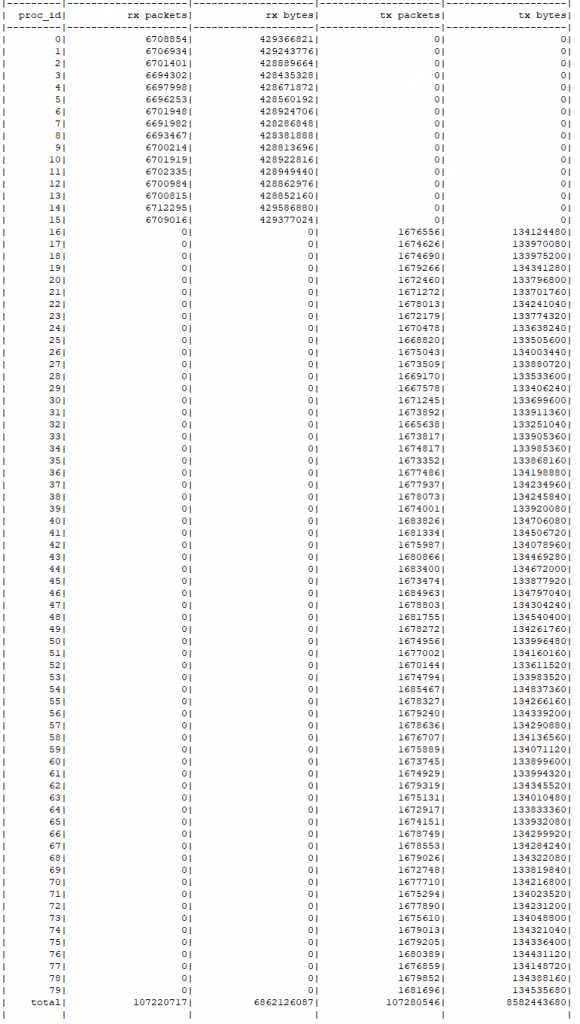

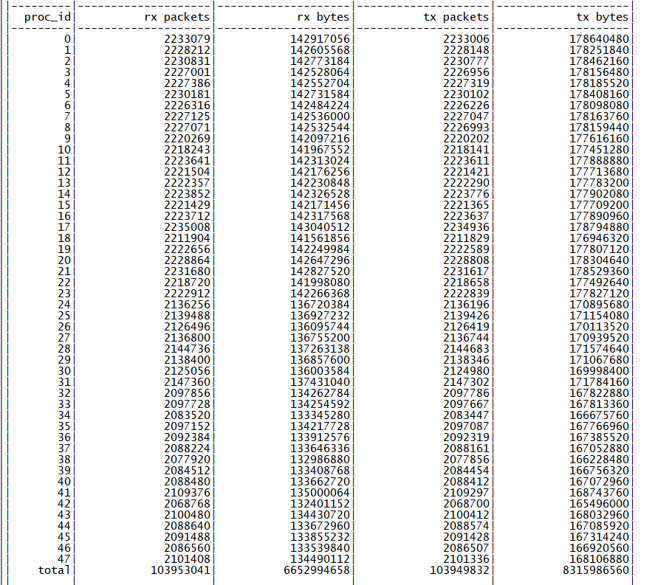
虽然两种架构的性能都达到了目标,但是综合考虑 RTC + Pipeline 只需要使用一个 NUMA 节点的 48 个物理核心即可,可以节省大量的 CPU 计算资源,且性能只是略低,所以最终在 FTDNS 中采用 RTC + Pipeline 的架构,常规配置 dispatcher 进程数量为 0 表示使用 RTC 模式,如有需要可以随时修改配置切换为 RTC + Pipeline 模式。
其他问题
- 本次测试使用的是 AMD CPU + Mellanox 的网卡,对于其他组合后续拿到其他组合的机型(如 Intel 的 CPU,Intel 或 Broadcom 的网卡等)也需要进行对应的测试,测试性能及验证队列数多于 PCIE 通道数时性能下降的问题,该问题也与 Intel 工程师有过交流。
- 跨 CPU 核心访问数据性能下降问题 Intel 工程师表示后续会有新的指令集可能对性能提升会有帮助。
- 后续还需要对 TCP DNS,或者说 F-Stack 在 100GE 机型上的短/长链接 TCP 进行测试和优化。