首先简单介绍下 DNS 解析中搜索引擎线路的作用,当代权威 DNS 的基本功能都包括分线路解析(也有智能解析、view、geo 等等名字) ,其中很多权威 DNS 服务商会提供针对搜索引擎蜘蛛抓取的线路(包括搜索引擎线路、SEO 优化、搜索引擎回源等等名字),主要目的是对普通用户返回 CDN 或其他通用的地址,而准对搜索引擎蜘蛛的抓取则直接返回源站的地址,可以提高权重、收录等目的。
搜索引擎蜘蛛在抓取网页前,首先要进行域名解析,获取目标域名的 IP 地址之后再进行抓取,此处需要涉及到蜘蛛使用的 LocalDNS 和目标域名使用的权威 DNS 两个部分的解析过程,首先介绍权威 DNS 解析过程。
权威 DNS 解析过程
权威 DNS 主要是依靠 LocalDNS 发送的 DNS 请求中的 IP 地址来进行分线路的解析的,而携带 IP 地址主要有两个位置,分别进行说明。
DNS 请求源地址
一个标准的 DNS 请求不管是 UDP 还是 TCP 协议,都必然要有其源 IP 地址,权威 DNS 服务器可以通过获取该地址来查询 IP 库和线路设置情况来进行分线路解析。
edns_client_subnet(ECS) 选项中携带 IP 地址
DNS 扩展协议中的 ECS 段可以在 DNS 请求包额外携带 IP 地址来供权威 DNS 获取并依此进行分线路解析,主要用于提升节点分布于全球的公共 DNS 来提升解析准确度,但是 ECS 的现状是大量权威 DNS 已经实现了对 ECS 的支持,但是 LocalDNS 对 ECS 的支持情况则很不乐观,除了 Google Public DNS 和 OpenDNS 有相对比较完整的支持外,其他包括运营商 DNS 和大部分其他公共 DNS 并没有很完整的支持 ECS 协议(ECS 协议支持情况可以参考之前的一篇文章《国内主要公共 DNS 支持 ECS 情况测试 – 20210315》)。
当然可知目前绝大部分的搜索引擎蜘蛛使用的 LocalDNS 也都是不支持 ECS 协议的,而权威 DNS 要正确解析蜘蛛访问的域名的线路主要就依赖蜘蛛使用的 LocalDNS 本身的外网出口 IP 来判断。下面再讨论蜘蛛使用的 LocalDNS 几种不同的场景。
蜘蛛使用的 LocalDNS
蜘蛛使用的 DNS 可能分为几种情况:
1. 使用蜘蛛独占的网段搭建 LocalDNS 进行解析
这种情况是对权威 DNS 的搜索引擎线路最友好的方式,该网段为蜘蛛独占,不与其他业务混用,尤其是公共DNS,目标域名的权威 DNS 只需要定期收集更新其蜘蛛使用的 LocalDNS 的外网出口 IP 即可达到很好的优化效果。
如果蜘蛛 IP 和 LocalDNS 的外网出口 IP 地址位于相同网段,通过搜索引擎官网公布或第三方收集的蜘蛛 IP、蜘蛛的 UA、IP 段的反解析结果等收集、验证、更新蜘蛛 IP 段即可。
如果 LocalDNS 的外网出口 IP 地址与蜘蛛 IP 位于不同网段,但是只要该网段依然是蜘蛛独占,可以通过一些技术手段来收集这些 LocalDNS 的外网出口 IP,如向 LocalDNS 请求 whoami.ip.dnspod.net,则返回结果即为该 LocalDNS 的外网出口 IP,如果 LocalDNS 支持 ECS,则会同时返回 LocalDNS 请求的源 IP 和携带的 ECS IP。
类似可以检测 LocalDNS 的外网出口 IP 的域名现网有多家大厂都有提供,仅返回结果的展示方式不一致。
但是想想就知道,蜘蛛全部独占相关的网段的可能性有多低,现网的相关测试数据也完全证明蜘蛛使用的网段大部分是也有其他业务在使用, 其实大部分其他业务复用蜘蛛 IP 段不会对搜索引擎线路优化有什么影响 ,除了公共 DNS。
2. 蜘蛛 LocalDNS 的外网出口 IP 网段和公共 DNS 网段重合
这种场景对同时提供搜索引擎服务和公共 DNS 服务的厂商是非常常见的,此处也不再进行举例说明,仅说明存在的问题。
目前从各种渠道获取到的蜘蛛 IP(包括其使用的 LocalDNS 外网出口 IP)在 IPv4(IPv6 本文不额外讨论) 中一般精度可达到 C 段 IP(/24),非常难达到非常准确的 /32 精度,这就导致权威 DNS 无法区分来访问的 IP 到底是蜘蛛来访问的还是普通用户使用公共 DNS 来访问的,从而无法给双方都解析到准确的结果,只能折衷选取一种策略。
举例说明,目前腾讯云 DNSPod 的解析策略是对此类 IP 不添加到蜘蛛 IP 库中,结果是蜘蛛很大概率无法获取搜索引擎线路设置的特定结果,但是也不会造成普通用户错误的获取到蜘蛛线路的解析结果,尤其是在其公共 DNS 服务的普通用户体量巨大的时候。
3. 直接使用公共 DNS 进行解析
公开的 LocalDNS 包括运营商 DNS 和其他公共 DNS,因为运营商 DNS 大多有源 IP 段必须为本运营商的限制,对于可能分布于各地的蜘蛛来说不是很好的选择,公共 DNS 则可以作为主要选择。
蜘蛛可以直接使用这些公共 DNS 进行解析或者自建的缓存 LocalDNS 本身不进行递归查询,只是将解析请求转发至公共 DNS 并缓存解析结果。
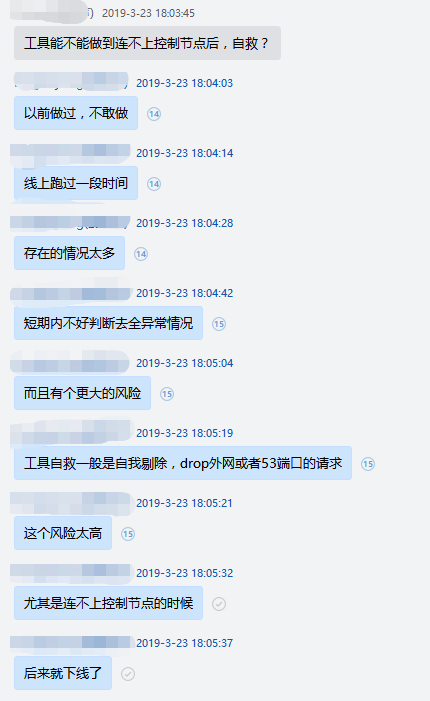
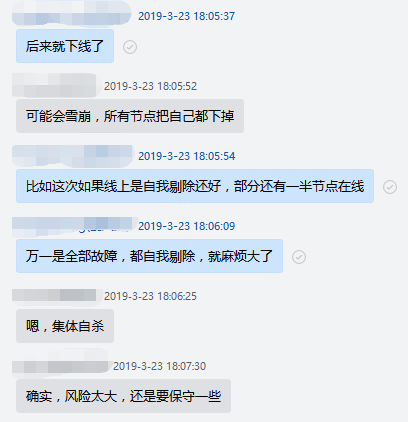
这个国庆假期互联网最大的新闻就是某不存在的公司 Facebook 全线业务宕机了 7 个小时,这其中有一个不起眼但是很关键的原因是其权威 DNS 节点在检测到部分网络异常(可以理解为控制面异常)后进行自我剔除操作,所有 DNS 节点“集体自杀”,从而导致 Facebook 自身及其他使用其权威 DNS 服务的业务全线异常。
这里会简单聊聊 DNSPod权威 DNS 的控制面异常时是如何处理的,包括曾经的思考与当前的实践经验,如何保障在出现类似问题的情况下尽量保障 DNS 服务的连续性,最终方案其实很简单,一点都不高大上,但好在简单实用。
权威 DNS 的控制面最主要的工作是同步用户记录的修改,不管是通过私有协议还是域传送,一旦控制面异常,边缘的 DNS 节点在故障期间无法同步用户最新的记录修改数据,终端用户就可能解析到旧的 IP 上,对业务造成一定影响,所以控制面故障时主要要解决的问题就是如何防止故障节点继续响应过期记录。
当前权威 DNS 大多使用多个 IP 同时提供服务,可能是 Anycast 集群,或者单地域集群,或者混合部署,都可以提供一定的容灾和负载均衡能力。而递归 DNS 对多个不同的权威 DNS 服务 IP 一般是通过 SRTT 方式来选择使用哪一个 IP 进行请求,可以自动剔除(减少请求)故障的权威 IP,一般只要权威的 IP 列表中有可用的 IP 且容量足够就可以正常进行递归解析。
所以最简单的处理方式就是直接踢掉控制面异常的权威 DNS 节点,即可保证递归不会解析到过期的数据,但是就是这最简单的踢掉故障节点的操作,其实也会涉及到很多的思考和实践经验,下面从头开始介绍。
控制面故障影响范围分类
按照影响 DNS 节点范围和处理方式来区分控制面故障的类型,主要就是两种类型,部分节点受影响和全部节点受影响。
部分节点受影响
这里可能有多种原因,最常见的如 DNS 节点与控制中心之间的网络异常,或者部分控制中心从节点故障,只影响少部分边缘的 DNS 节点的控制面数据同步,那么这时候故障 DNS 节点自救做自我剔除,将自己从服务集群中摘除貌似完全没有影响,然后自动/手动切换到其他正常的控制节点或者等待故障的控制节点恢复,再恢复 DNS 节点的对外服务即可。
直接通过防护系统(宙斯盾)或运营商防护接口在某地域或全地域封禁该IP,此时虽然对应节点的 IP 不可用,但是 LocalDNS 可以通过文章开头提到的 SRTT 机制去其他正常节点请求,不影响总体解析。
前面的处理方式都有一个前提,就是其他节点容量足够,但是如果剩余节点容量不足怎么办,此时处理方案是不对 DNS 节点进行下线处理,虽然可能导致部分 DNS 请求会解析到过时的记录,但是有变化的记录毕竟是少数,需要优先保证整个大盘的解析正常。此场景在某些极端情况下有一定的出现的可能,比如整个平台遭受持续超大量的 DDoS 攻击时,同时这台服务器出现了控制面故障,根据具体情况评估影响后可能采取此不处理下线的方式。
在权威解析控制台及注册局(商)出删除该 IP,因为 TTL 很长,一般不考虑。
控制中心完全故障导致所有节点控制面故障
类似此次的 Facebook 的最初始故障,如判断确实是控制中心就是无法连接,无法同步数据,那么也只能降级服务,不对 DNS 节点进行下线处理,等待控制中心恢复。
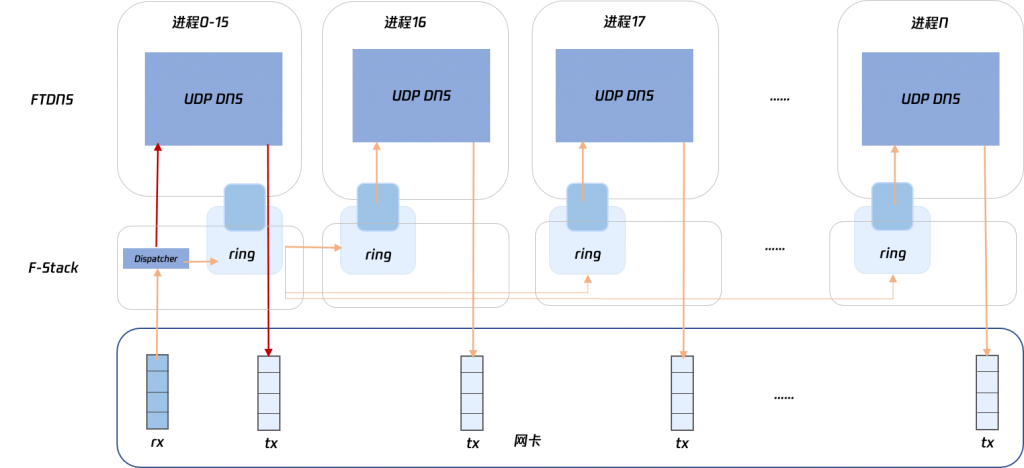
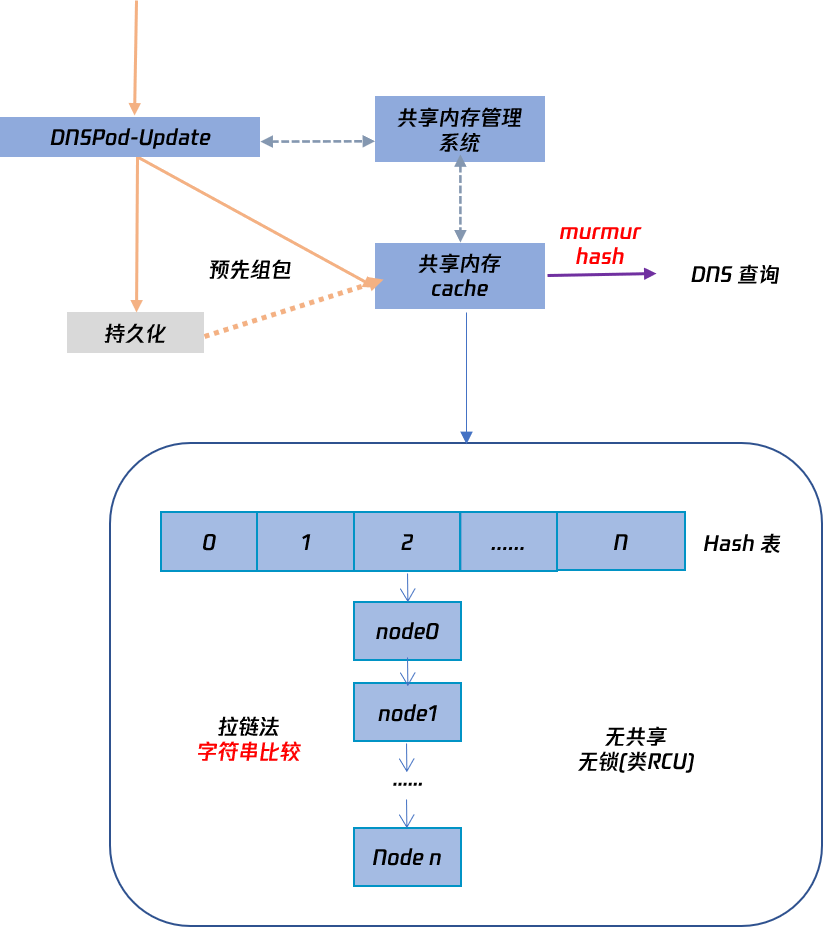
既然网卡开启 16 个接收队列时可以达到最好的接收性能,那么很自然的一个想法,将业务程序的架构由 Run to completion 改为 Pipeline 架构,只开启 16 个接收队列专门用于接收 DNS 请求,再通过 rte ring 将请求报转发到其他业务进程进行实际的 DNS 解析后再直接发送出去,虽然单进程性能会因为 CPU cache miss 的问题急剧下降,但是可以使用更多的 CPU 运行业务进程来弥补,架构简图如下所示。
Pipeline 架构 【注】红色箭头为与 RTC 架构的数据包流向的区别
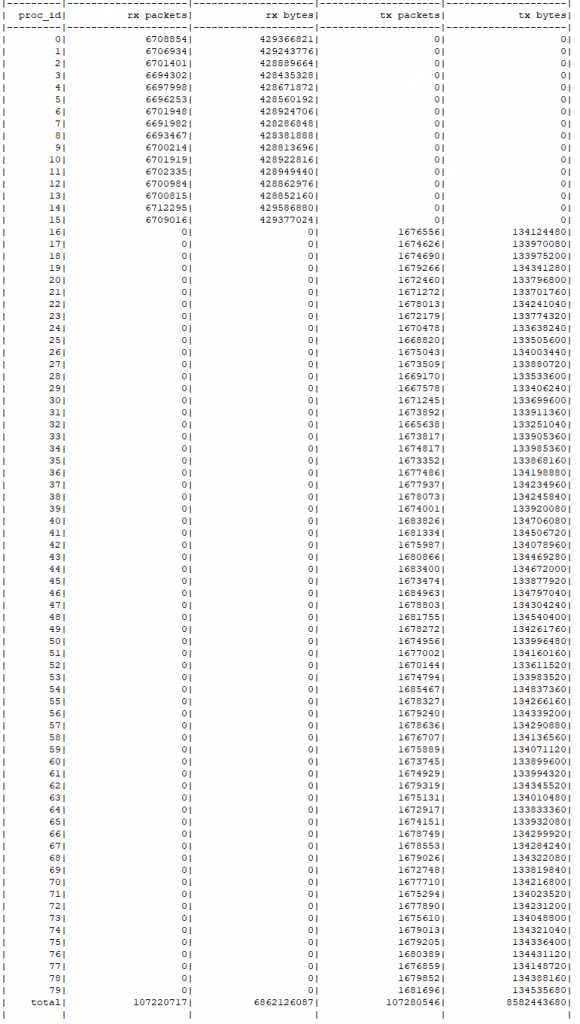
F-Stack 本身已经提供了函数 ff_regist_packet_dispatcher() 用于对接收到的数据包进行重新分发,且 FTDNS 中已经使用来直接进行 UDP DNS 的解析,稍作修改前 16 个进程仅分发,不再处理 DNS 解析即可,但是实际测试发现转发性能太差,perf 分析主要是软分发回调函数是对数据包一个个进行处理的,性能较差。
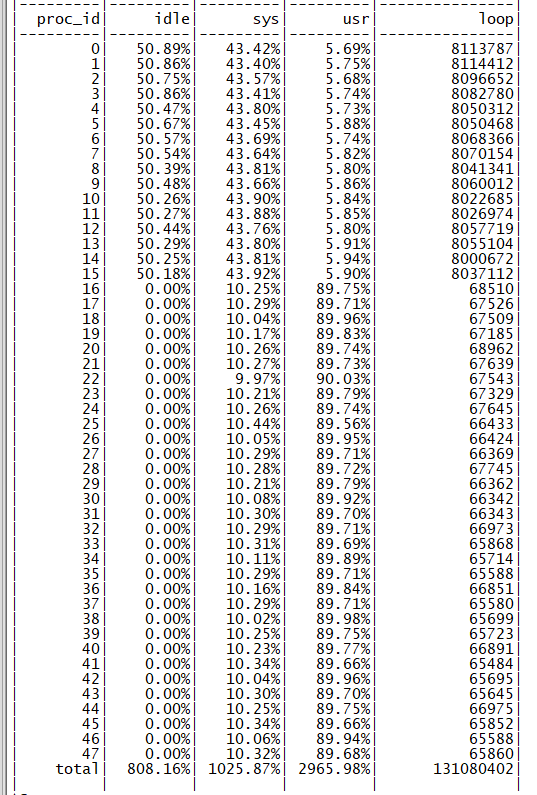
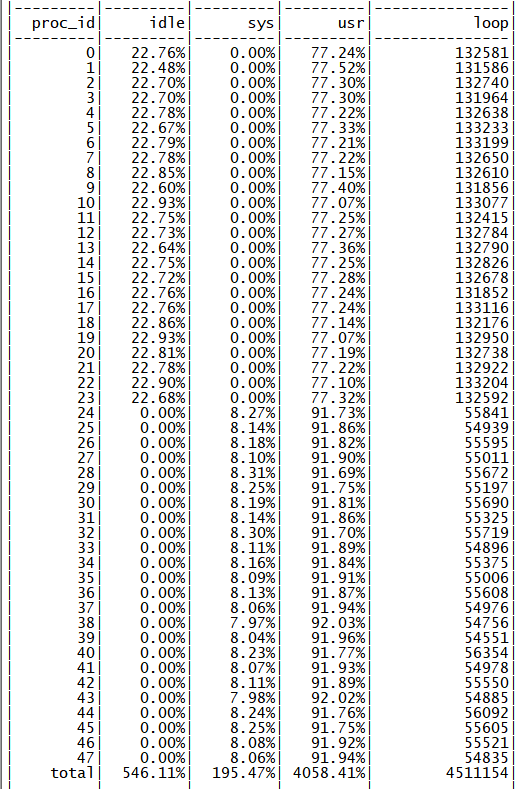
此时 48 核为同一个 NUMA 节点的物理核心,全部使用后性能可以达到 68M QPS,单核性能下降约 12%,符合前期的心里预期,查看 perf 信息,热点也符合预期(如下图所示)。
跨 CPU 访问数据热点
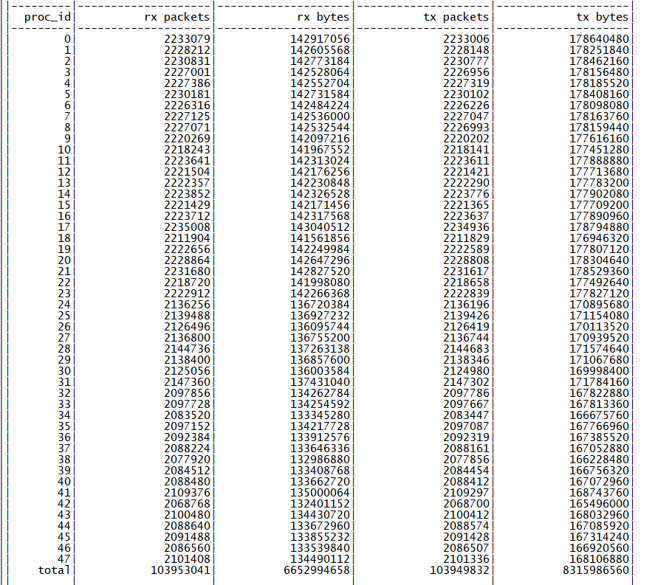
如果有更多业务进程,是否就可以达到小目标了呢?因为机器架构限制的原因,本物理核的另外 48 个超线程核心很难使用到,且根据历史经验,即使使用性能提升也非常小,所以直接继续使用另一个 NUMA 节点的 CPU 的物理核心进行进一步测试,可以用到 80 个 CPU 核心,对应的收包分发线程调整为 20 进程,测试得到 Pipeline 的最优性能如下图所示。
因为透明代理的源 IP 是实际客户的 IP,在实际服务接受处理完响应包返回时会返回给实际的客户 IP,所以需要配置将回包发到 Nginx 进行处理,这里的上游服务为本机服务,需进行如下配置。如上游在其他服务器上,可以查看参考资料中文章并进行对应配置。
# 新建一个 DIVERT 给包打标签 iptables -t mangle -N DIVERT; iptables -t mangle -A DIVERT -j MARK --set-mark 1; iptables -t mangle -A DIVERT -j ACCEPT; # 把本机 TCP 服务的回包给 DIVERT 处理 iptables -t mangle -A OUTPUT -p tcp -m tcp --sport 8081 -j DIVERT # 有标签的包去查名为 100 的路由表 ip rule add fwmark 1 lookup 100 # 100的路由表里就一条默认路由,把所有包都扔到lo网卡上去 ip route add local 0.0.0.0/0 dev lo table 100
F-Stack(FreeBSD) 路由配置
F-Stack(FreeBSD) 上游回包路由配置,
# upstream 为本机时 # 假设 f-stack-0 的 IP 为 192.168.1.3,将 upstream 往外发的所有出包都转发到 F-Stack Nginx 监听的 IP 和端口即可 # 因为转发到本机地址时目的端口会被忽略,可不设置端口 ff_ipfw add 100 fwd 192.168.1.3,8080 tcp from 192.168.1.2 8081 to any out # upstream 为其他机器时 # 将 upstream 通过设置网关或者 IP 隧道(需额外进行隧道配置)等方式发过来的所有入包都转发到 F-Stack Nginx 监听的 IP 和端口即可 # 因为转发到本机地址时目的端口会被忽略,可不设置端口 ff_ipfw add 100 fwd 192.168.1.3 tcp from 192.168.1.2 8081 to any in via f-stack-0