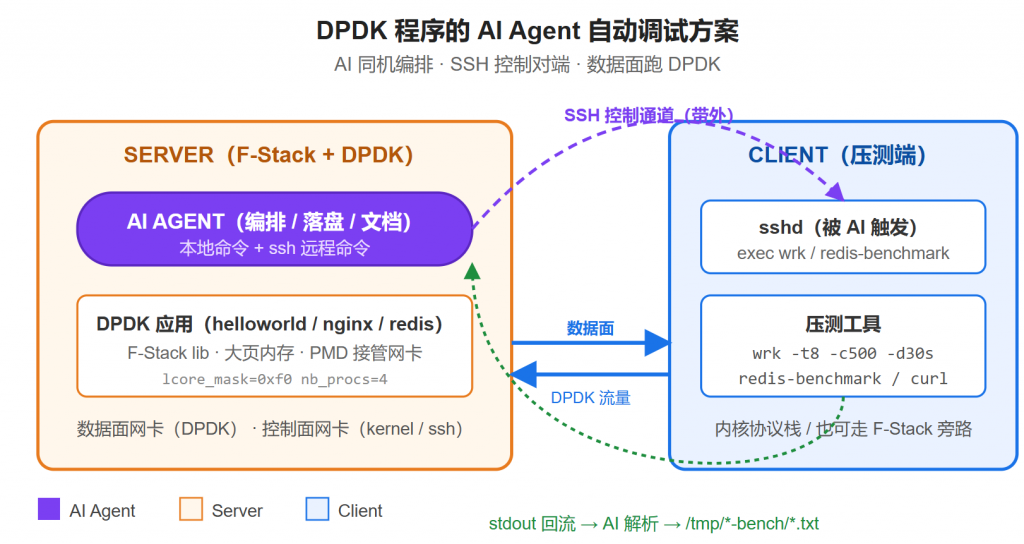
2026.05.26本文章已经更新
跳票许久许久的LD_PRELOAD功能模块(后续以 libff_syscall.so 代替)在 F-Stack dev 分支的 adapter/sysctall 目录下已经提交,支持 hook 系统内核 socket 相关接口的代码,降低已有应用迁移到 F-Stack 的门槛。下面将分别进行具体介绍, 主要包括libff_syscall.so 相关的架构涉及其中的一些思考,支持的几种模式以及如何使用等内容。
总体结论:
原有应用程序的接入门槛比原本的 F-Stack 有所降低,大部分情况下可以不修改原有的用户应用程序和 F-Stack lib 的代码,而是仅修改libff_syscall.so相关代码即可适配。 可以支持多 F-Stack 实例(即原 F-Stack 应用程序进程),每个 F-Stack 实例可以对应 1 个或多个用户应用程序。为了达到最佳的性能,建议一个用户应用程序(进程或线程)对应一个 fstack 实例应用程序,即为一组应用实例。 每组应用实例的性能会略高于系统内核的性能,与单个标准 F-Stack 应用进程互有高低;单机整体的性能相比系统内核仍有较大的优势,但与标准 F-Stack 仍有差距。新的每组应用实例需要运行在两个 CPU 核心上,而标准 F-Stack 应用进程只需要运行在一个 CPU 核心上,总体而言性价比不高 ,是否使用可以视各业务的具体情况而定。 Nginx 600 字节的 body 内存应答测试中,长连接中相同数量的新应用实例组 略高 于标准 F-Stack 应用进程,短连接中相同数量的新应用实例组 则略低 于标准 F-Stack 应用进程,见 Nginx 接入介绍章节,但使用的 CPU 几乎翻倍。 已知限制
自 2023 年以来 libff_syscall.so 持续迭代,原本作为开放问题的多个能力(如 fork、accept4、__recv_chk 系列、epoll polling 模式以及 lock-free ring IPC 等)已经实现,详见下文 功能更新历程 。下列限制仍在跟踪,欢迎社区共同完善:
进程结束时仍可能存在内存泄漏与死锁风险。 部分接口(如 sendmsg、readv、readmsg 等)线上场景使用较少,尚未做充分的性能优化与测试,仍需进一步打磨(较新加入的 accept4、__recv_chk、__read_chk、__recvfrom_chk 等已覆盖)。 项目在准生产环境中持续迭代,欢迎社区提供更长时间运行的稳定性反馈。 在多 F-Stack 实例同时运行时暂不能作为客户端使用,例如 Nginx 的 proxy 场景;参考的改造思路如下: @铁皮大爷:之前实现过类似的逻辑,在 hook 内再加一层 RSS。延迟建立 socket(仅在确定目的与来源后再选择由哪个 F-Stack 作为 worker 进程),同时要求网卡接收侧开启 RSS 对称哈希,保证出入方向能落到同一个 F-Stack worker。app -> socket:暂存 socket 操作,创建 fd(fd1)返回给用户。 app -> bind:暂存 bind 操作,将 bind 参数与 fd1 绑定后返回给用户。 app -> connect:在 fd1 上追加 connect 参数,按 RSS 对称哈希选定某个 F-Stack 进程(worker),将暂存的 socket、bind、connect 一并交给该 F-Stack 进程处理并等待同步结果。 功能更新历程 (2023-05-04 ~ 2026-05-25)
以下汇总自 v1.22 以来 adapter/syscall/ 目录的主要变更。
新功能
Lock-free rte_ring IPC(FF_USE_RING_IPC) :以 DPDK SPSC ring 替代原先基于信号量的共享内存 IPC,从 fstack 主循环中彻底移除全局 ff_so_zone->lock。多核短/长连接实测中 ring 与 sem 性能相当或略低 2–4%,无跨 worker 锁竞争,并天然免疫启动期自旋锁饥饿。Ring 分支默认启用 v3.4 的优化(D2:sc->completion 唤醒;D5:内联 rte_ring_empty 快速空判断;D6:内联 dequeue burst 与 dispatch)。编译开关见附录 FF_USE_RING_IPC,完整设计与性能分析见 docs/ld_preload_ring_spec/。epoll polling 模式fork 支持struct thread,行为更接近 Linux kernel,解除了原先 LD_PRELOAD 下 fork 使用受限的状况。accept4 及 SOCK_CLOEXEC / SOCK_NONBLOCK 支持accept4 hook,并在 ff_socket 上支持 LINUX_SOCK_CLOEXEC / LINUX_SOCK_NONBLOCK 标志位。glibc _FORTIFY_SOURCE 系列 hook :新增 __recv_chk、__read_chk、__recvfrom_chk,使开启 -D_FORTIFY_SOURCE 编译的应用能在 LD_PRELOAD 下正常工作。功能完善与缺陷修复
FF_KERNEL_EVENT 模式下 kernel epoll fd 泄漏修复ff_hook_close 在启用 FF_KERNEL_EVENT 时同步关闭系统侧 epoll fd,解决长时间运行 Nginx 场景下观察到的内核 fd 泄漏。ff_hook_syscall.c 中 cplen 计算修复ff_hook_accept。ff_hook_recvfrom 中 sh_fromlen 未初始化修复ff_sys_recvfrom 之前初始化 sh_fromlen,修复返回 -1 的回归问题。ioctl 函数原型冲突的编译错误修复(#942)Ring IPC 启动期饥饿修复 :在 FF_MULTI_SC + idle_sleep = 0 场景下,nginx worker 在 attach 第二个 fstack 实例的 ff_so_zone 时可能表现为死锁;sem 路径在确认无在用 socket context 时做条件性的 unlock → pause → lock,消除饥饿且对正常负载零影响。Ubuntu 22.04 / kernel 5.19 / gcc 11.4 编译错误修复 :包含 pre-C99 声明问题,参考 #777。其他零碎编译 / 日志 / Makefile / 头文件打磨 :包括 syscall 目录编译问题修复、日志清理,以及一系列围绕 ff_hook_syscall.c、ff_socket_ops.c、ff_socket_ops.h、ff_linux_syscall.c、ff_sysproto.h、ff_declare_syscalls.h 与 Makefile 的细节改进。libff_syscall.so 的编译先设置好FF_PATH和PKG_CONFIG_PATH环境变量
export FF_PATH=/data/f-stack
在adapter/sysctall目录下直接编译即可得到ibff_syscall.so的相关功能组件
cd /data/f-stack/adapter/sysctall
下面将分别进行介绍各个组件的主要作用
fstack 实例应用程序
fstack应用程序对标的是标准版 F-Stack 中的应用程序,其运行与普通的 F-Stack 应用程序完全相同,包括配置文件及其多进程(每进程即为一个实例)的运行方式等, 具体运行方式可以参考 F-Stack 主目录的 README, 在执行 LD_PRELOAD 的用户应用程序前必须先运行 fstack实例应用程序。
fstack 应用程序的作用主要是底层对接 F-Stack API,其主函数ff_handle_each_context即为普通 F-Stack 应用的用户层 loop 函数,非空闲时或每间隔 10ms (受 HZ参数影响) 时会调用该函数去循环处理与 APP 对接的上下文,如果 APP 有对应的 API 请求,则调用实际的 F-Stack API 进行处理。
与 libff_syscall.so用户应用进程间通信使用 DPDK 的 rte_malloc 分配的 Hugepage 共享内存进行。
该函数对 libff_syscall.so 的整体性能有至关重要 的影响,目前是复用了 F-Stack 主配置文件(config.ini)中的 pkt_tx_dalay参数,死循环并延迟该参数指定的值后才会回到 F-Stack 的其他处理流程中。
如果想提高 libff_syscall.so的整体性能,那么fstack实例应用程序与 APP 应用程序的匹配十分重要,只有当一个ff_handle_each_context循环中尽量匹配一次循环的所有事件时才能达到最优的性能,这里需要调十分精细的调优,但是目前还是粗略的使用 pkt_tx_dalay参数值。
【提示】pkt_tx_dalay参数的默认值为 100us, 较适合长连接的场景。如果是 Nginx 短链接的场景,则应考虑设置为 50us,可以可获得更好的性能。当然不同的用用场景如果想达到最优的性能,可能需要业务自行调整及测试。复用该参数也只是临时方案,后续如果有更优的方案,则随时可能进行调整。
libff_syscall.so
该动态库主要作用是劫持系统的 socket 相关接口,根据 fd 参数判断是调用 F-Stack的相关接口(通过上下文 sc 与 fsack 实例应用程序交互)还是系统内核的相关接口。
与fstack实例应用进程间通信使用 DPDK 的 rte_malloc 分配的 Hugepage 共享内存进行。
【注意】在第一次调用相关接口时分配相关内存,不再释放,进程退出时存在内存泄漏的问题,待修复。
F-Stack用户的应用程序 (如 helloworl 或 Nginx)设置 LD_PRELOAD劫持系统的 socket 相关 API 时使用,即可直接接入 F-Stack 开发框架,可以参考如下命令:
export LD_PRELOAD=/data/f-stack/adapter/syscall/libff_syscall.so
确保 fstack实例应用程序已经正确运行的前提下,然后启动用户应用程序。
当然如果是改造用户的 APP 使用 kqueue代替 Linux 的 epoll 相关事件接口时,也可以在用户 APP 中直接链接该运行库, 可以参考相关示例程序helloworld_stack和helloworld_stack_thread_socket对应的源文件main_stack.c和main_stack_thread_socket.c,因为不是使用的LD_PRELOAD, 所以本文档不再详细介绍。
【重要提示】一组对应的fstack应用程序和用户应用程序最好运行在同一个 CPU NUMA 节点 的不同物理核 上,其他场景(运行在同一个CPU核心、两个 CPU 核心跨 NUMA 节点,物理核和超线程核混用)都无法达到一组实例的最佳性能。
特别的,如果 CPU 物理核心比较缺乏,可以考虑一组实例分别运行在对应的一组 CPU 的物理核心和 HT 核心上,虽然单组实例性能会有所下降(约 20% 左右),但可以使用更多的 CPU 核心,单机总性能可能会有所提升。 DEMO 演示程序 helloworld_stack*
其他编译生成的hello_world开头的可执行文件为当前libff_syscall.so支持的几种不同运行模式的相关演示程序,下一节进行具体介绍。
F-Stack LD_PRELOAD 支持的几种模式
为了适应不同应用对 socket 接口的不同使用方式,降低已有应用迁移到 F-Stack 的门槛,并尽量提高较高的性能,目前 F-Stack 的 libff_syscall.so 主要支持以下几种模式,支持多线程的 PIPELINE 模式、线程(进程)内的 RTC(run to completion)模式、同时支持 F-Stack 和内核 socket 接口的 FF_KERNEL_EVENT 模式和类似内核 SO_REUSEPORT 的 FF_MULTI_SC 模式。
支持多线程的 PIPELINE 模式
该模式为默认模式,无需额外设置任何参数直接编译libff_syscall.so即可。
在此模式下,socket 相关接口返回的 fd 可以在不同线程交叉调用 ,即支持 PIPELINE 模式,对已有应用的移植接入更友好,但性能上相应也会有更多的损失。
该模式除了单进程运行方式外,同时可以支持用户应用程序多进程方式运行 ,每个用户进程对应一个fstack实例应用程序的实例,更多信息可以参考附录的运行参数介绍。
【注意】以此默认方式接入 F-Stack 的应用程序只能使用 F-Stack 的 socket 网络接口,而不能使用系统的 socket 接口。
hook 系统 epoll 接口
对于已有的 Linux 下的应用,事件接口都是一般使用的是epoll相关接口,对于没有更多特殊要求的应用程序,可以直接使用默认的编译参数编译libff_syscall.so后使用,参考 DEMO 程序helloworld_stack_epoll, 代码文件为main_stack_epoll.c。
【注意】F-Stack 的epoll接口依然为kqueue接口的封装,使用上依然与系统标准的epoll事件接口有一定区别,主要是事件触发方式和multi accept的区别。
使用 kqueue
当然libff_syscall.so除了支持使用LD_PRELOAD方式 hook 系统的 socket 接口的方式使用,也支持普通的链接方式使用,此时除了可以使用系统的epoll事件接口之外,还可以使用 F-Stack(FreeBSD)具有的kqueue事件接口,参考 DEMO 程序helloworld_stack, 代码文件为main_stack.c。
该使用方式的性能比LD_PRELOALD使用系统epoll接口的方式有略微的性能提升。
线程(进程)内的 RTC(run to completion)模式
该模式需要设置额外的编译参数后来编译libff_syscall.so才能开启,可以在adapter/sysctall/Makefile中使能FF_THREAD_SOCKET或执行以下 shell 命令来开启。
export FF_THREAD_SOCKET=1
在此模式下,socket 相关接口返回的 fd 仅可以在本线程内调用 ,即仅支持线程内的 RTC 模式,对已有应用的移植接入门槛稍高,但性能上相应也会有一定的提升,适合原本就以 RTC 模式运行的应用移植。
同样的,该模式除了单进程运行方式外,同时可以支持用户应用程序多进程方式运行 ,每个用户进程对应一个fstack实例应用程序的实例,更多信息可以参考附录的运行参数介绍。
【注意】以此默认方式接入 F-Stack 的应用程序同样只能使用 F-Stack 的 socket 网络接口,而不能使用系统的 socket 接口。
hook 系统 epoll 接口
其他同默认的 PIPELINE 模式,可以参考 DEMO 程序helloworld_stack_epoll_thread_socket, 代码文件为main_stack_epoll_thread_socket.c。
使用 kqueue
其他同默认的 PIPELINE 模式,可以参考 DEMO 程序helloworld_stack_thread_socket, 代码文件为main_stack_thread_socket.c。
FF_KERNEL_EVENT 模式
该模式可以同时支持 F-Stack 和系统内核的 socket 接口,需要设置额外的编译参数后来编译libff_syscall.so才能开启,可以在adapter/sysctall/Makefile中使能FF_KERNEL_EVENT或执行以下 shell 命令来开启。
export FF_KERNEL_EVENT=1
在此模式下,epoll相关接口在调用 F-Stack 接口的同时会调用系统内核的相关接口,并将 F-Stack 返回的 fd 与系统内核返回的 fd 建立映射关系,主要为了支持两个场景:
用户应用程序中有控制 fd 与 数据 fd 使用相同的 epoll fd, 如 Nginx。 希望本机也可以同时访问用户应用程序监听的网络接口。如果希望单独与本机系统内核进行普通网络通信,需要额外调用socket接口,并需要指定type | SOCK_KERNEL参数,并为返回的 fd 单独调用 bind()、listen()、epoll_ctl()等接口,参考 DEMO 程序helloworld_stack_epoll_kernel, 代码文件为main_stack_epoll_kernel.c 【注意1】F-Stack 中 FreeBSD 的内核参数 kern.maxfiles不应该大于 65536(原默认值为 33554432),以保证 F-Stack 的 epoll fd 到系统内核的 epoll fd 的正确映射。
【注意2】Nginx 的无缝接入需要开启此模式,因为在 Nginx 中有多个控制 fd 与 数据 fd 使用相同的 epoll fd。
FF_MULTI_SC 模式
该模式为 Nginx 等使用内核SO_REUSEPORT且fork子进程 worker 运行等特殊的设置为设置,需要设置额外的编译参数后来编译libff_syscall.so才能开启,可以在adapter/sysctall/Makefile中使能FF_MULTI_SC或执行以下 shell 命令来开启。
export FF_MULTI_SC=1
在此模式下,用户应用程序与fstack实例相关联的上下文sc除了保存在全局变量sc中之外,会额外保存在全局的scs数组中,在fork()子进程 worker 时会使用 current_worker_id设置sc变量为对应 worker 进程 fd 对应的 sc,供子进程复制及使用。
Nginx 的reuseport模式的主要流程为,主进程为每个 worker 分别调用 socket()、bind()、listen()等接口,并复制到 worker 进程,而后 woker 进程各自调用epoll相关接口处理各自的 fd, 需要各自 fd 对应的上下文 sc 才能正确运行。
【注意】Nginx 的无缝接入需要同时开启 FF_THREAD_SOCKET 和 FF_MULTI_SC 模式。
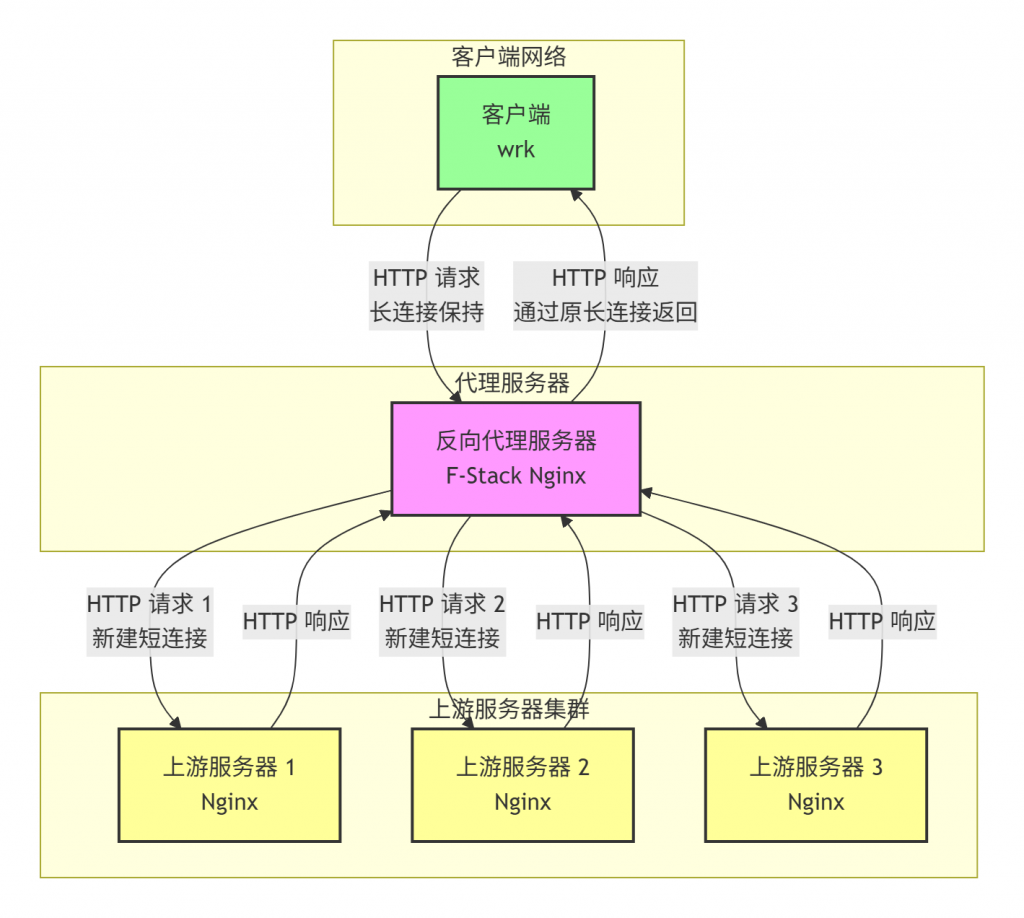
Nginx 接入libff_syscall.so介绍
Nginx(以 F-Stack 默认携带的 Nginx-1.16.1 为例)目前可以不修改任何代码直接以LD_PRELOAD动态库libff_syscall.so的方式接入 F-Stack,以下为主要步骤及效果。
编译libff_syscall.so
需要同时开启 FF_THREAD_SOCKET 和 FF_MULTI_SC 模式进行编译
export FF_PATH=/data/f-stack
配置nginx.conf
以下为主要需要注意及修改的相关配置参数示例(非全量参数):
user root;
【注意】此处的 reuseport作用是使用多个不同的 socket fd, 而每个 fd 可以对接不同的fstack实例应用程序的上下文sc来分散请求,从而达到提高性能的目的。与系统内核的reuseport行为异曲同工。
运行
假设运行4组 Nginx – fstack 实例应用程序,可以简单按照以下步骤进行
运行 fstack 实例 设置config.ini中的lcore_mask=f00,即使用 CPU 核心 9-11, 其他配置按照标准 F-Stack 配置进行。 参考以下命令启动 fstack 实例,并等待一段时间待 fstack 主进程和子进程都启动完成 cd /data/f-stack
bash ./start.sh -b adapter/syscall/fstack运行 Nginx 参考以下命令配置libff_syscall.so所需的环境变量 export LD_PRELOAD=/data/f-stack/adapter/syscall/libff_syscall.so # 设置 LD_PRELOAD libff_syscall.so
export FF_NB_FSTACK_INSTANCE=4 # 设置有 4 个 fstack 实例应用程序,前面 nginx.conf 中也配置了 4 个worker /usr/local/nginx/sbin/nginx # 启动 Nginx性能对比
测试环境
CPU:Intel(R) Xeon(R) CPU E5-2670 v3 @ 2.30GHz * 2
网卡:Intel Corporation Ethernet Controller 10-Gigabit X540-AT2
OS :TencentOS Server 3.2 (Final)
内核:5.4.119-1-tlinux4-0009.1 #1 SMP Sun Jan 23 22:20:03 CST 2022 x86_64 x86_64 x86_64 GNU/Linux
Nginx长连接
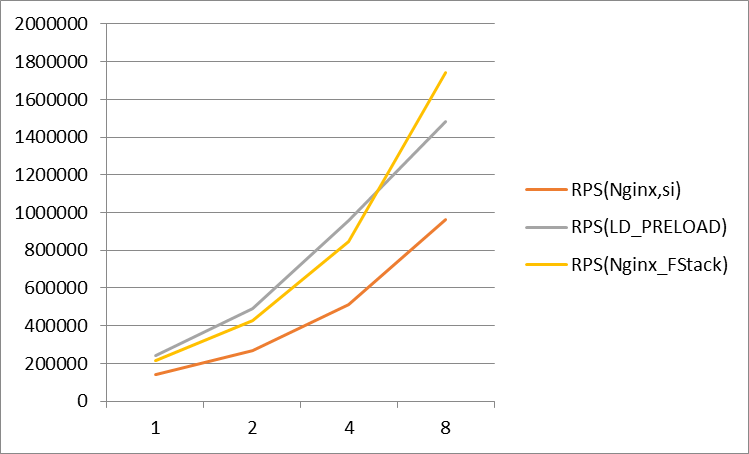
body 大小为 602 字节(不包括 http 头等)。 LD_PRELOAD 实际使用的 CPU 为几乎横轴 CPU 核心数的双倍,系统内核均衡软中断实际使用的 CPU 也远高于 worker 数量对应的 CPU 核心数量。 限于时间所限,其中 LD_PRELOAD 的测试数据为以上测试环境的数据,其他为历史 40G 测试环境的数据,后续会更新为相同测试环境的数据。 受网卡硬件所限,8核 LD_PRELOAD 测试带宽已经接近 10G 网卡线速 (服务端出带宽9.xG,148万 RPS), 导致的与标准 F-Stack 的数据差异,实际CPU尚有一些空闲,后续应使用 40G/100G 网卡进行对比测试 pkt_tx_delay 参数为 100us。 Nginx短链接
body 大小为 602 字节(不包括 http 头等)。 LD_PRELOAD 实际使用的 CPU 为几乎横轴 CPU 核心数的双倍,系统内核均衡软中断实际使用的 CPU 也远高于 worker 数量对应的 CPU 核心数量。 受 CPU 硬件所限(12C24HT * 2),LD_PRELOAD 测试只能测试12组应用实例组,即使用了全部 CPU 的物理核心,无法进行更多实例组的测试。 8核之后 LD_PRELOAD 的性能不如标准 F-Stack 的性能,最主要是受用户应用程序和fstack应用程序的匹配度不高(ff_handle_each_context的循环次数及时间等)影响很大,并未完全达到性能极致,如果持续的精细化调整可以进一步提高性能,但是通用性也不高。 pkt_tx_delay 参数由 100us 调整到 50us。 附录:详细参数介绍
编译参数
本段总体介绍各个编译选项,所有参数都可以在adapter/sysctall/Makefile中开启或通过 shell 命令设置环境变量来开启。
DEBUG
开启或关闭 DEBUG 模式,主要影响优化和日志输出等, 默认关闭。
export DEBUG=-O0 -gdwarf-2 -g3
默认的优化参数为
-g -O2 -DNDEBUG
FF_THREAD_SOCKET
是否开启线程级上下文sc变量,如果开启,则 socket 相关 fd 只能在本线程中调用,一般可以略微提高性能, 默认关闭。
export FF_THREAD_SOCKET=1
FF_KERNEL_EVENT
是否开启epoll相关接口在调用 F-Stack 接口的同时调用系统内核的相关接口,并将 F-Stack 返回的 fd 与系统内核返回的 fd 建立映射关系, 默认关闭,主要为了支持两个场景:
用户应用程序中有控制 fd 与 数据 fd 使用相同的 epoll fd, 如 Nginx。 希望本机也可以同时访问用户应用程序监听的网络接口。 export FF_KERNEL_EVENT=1
FF_MULTI_SC
在此模式下,用户应用程序与fstack实例相关联的上下文sc除了保存在全局变量sc中之外,会额外保存在全局的scs数组中,在fork()子进程 worker 时会使用 current_worker_id设置sc变量为对应 worker 进程 fd 对应的 sc,供子进程复制及使用。 默认关闭。
export FF_KERNEL_EVENT=1
FF_USE_RING_IPC
是否将 libff_syscall.so 与 fstack 实例之间的 IPC 从原有的信号量+共享内存方案切换为 lock-free 的 DPDK SPSC rte_ring,默认关闭。
export FF_USE_RING_IPC=1
启用该开关时,v3.4 的 ring 路径优化均作为默认行为合入(基于 sc->completion 的唤醒、内联 rte_ring_empty 快速空判断、以及内联 dequeue burst 与 dispatch),无需额外子开关。
性能摘要:在 LD_PRELOAD + FF_MULTI_SC 且 nginx worker 与 fstack 实例 1:1 的部署形态下,ring 与 sem 在 1 / 2 / 4 核短/长连接实测中相差均在 2–4% 以内。Ring 路径的主要价值是结构性的:主循环 lock-free、天然免疫启动期自旋锁饥饿、且不需要 fstack 侧的 zone 级锁。对于每个 worker 拥有独立 fstack 实例的生产部署,sem 路径仍是推荐配置;ring 路径主要作为未来”单进程内多线程共享 sc”或”多进程间共享 sc(worker 数量多于 fstack 实例数量)”扩展场景的预留能力。完整设计与性能分析见 docs/ld_preload_ring_spec/。
运行参数
通过设置环境变量设置一些用户应用程序需要的参数值,如果后续通过配置文件配置的话可能需要修改原有应用,所以暂时使用设置环境变量的方式。
LD_PRELOAD
设置 LD_PRELOAD 的运行库,再运行实际的应用程序,可以参考以下命令
export LD_PRELOAD=/data/f-stack/adapter/syscall/libff_syscall.so
如果想通过gdb调试应用程序,则可以参考以下命令
export LD_PRELOAD=
FF_NB_FSTACK_INSTANCE
设置fstack实例应用程序的实例数,用于和用户应用程序的进程/线程等 worker 数量相匹配,默认1。
export FF_NB_FSTACK_INSTANCE=4
建议用户应用程序 worker 数量与fstack实例应用程序尽量 1:1 配置,可以达到更好的性能。
FF_INITIAL_LCORE_ID
配置用户应用程序的 CPU 亲和性绑定的起始 CPU 逻辑 ID,16进制,默认0x4(0b0100),即 CPU 2。
export FF_INITIAL_LCORE_ID=0x4
如果用于应用程序可以配置 CPU 亲和性,则可以忽略该参数,如 Nginx 配置文件中的worker_cpu_affinity参数。
FF_PROC_ID
配置用户应用程序的进程 ID,可以配合FF_INITIAL_LCORE_ID参数设置 CPU 亲和性的绑定,10进制递增,默认0。
export FF_PROC_ID=1
如果用于应用程序可以配置 CPU 亲和性,则可以忽略该参数,如 Nginx 配置文件中的worker_cpu_affinity参数。
致谢
特别感谢以下外部贡献者自 2023-05-04 以来通过 pull request 与 commit 对 libff_syscall.so 做出的实质性扩展:
liujinhui-job fork 支持(PR #887)、accept4 及 SOCK_CLOEXEC / SOCK_NONBLOCK 支持、__recv_chk / __read_chk / __recvfrom_chk 系列 _FORTIFY_SOURCE hook、epoll polling 模式、ff_hook_recvfrom 中 sh_fromlen 未初始化修复(PR #872),以及围绕 ff_hook_syscall.c、ff_socket_ops.c、ff_socket_ops.h、ff_linux_syscall.c、ff_sysproto.h、ff_declare_syscalls.h 与 Makefile 的一系列细节优化。zhaozihanzzh ff_hook_syscall.c 中的 cplen 计算错误(并将代码风格统一到 ff_hook_accept),以及在 FF_KERNEL_EVENT 模式下 ff_hook_close 内的 kernel epoll fd 泄漏问题。上述贡献显著提升了 LD_PRELOAD 路径的完整性、正确性以及对 Nginx 的友好程度,欢迎社区继续提交 pull request 与建议。
如果用于应用程序可以配置 CPU 亲和性,则可以忽略该参数,如 Nginx 配置文件中的worker_cpu_affinity参数。