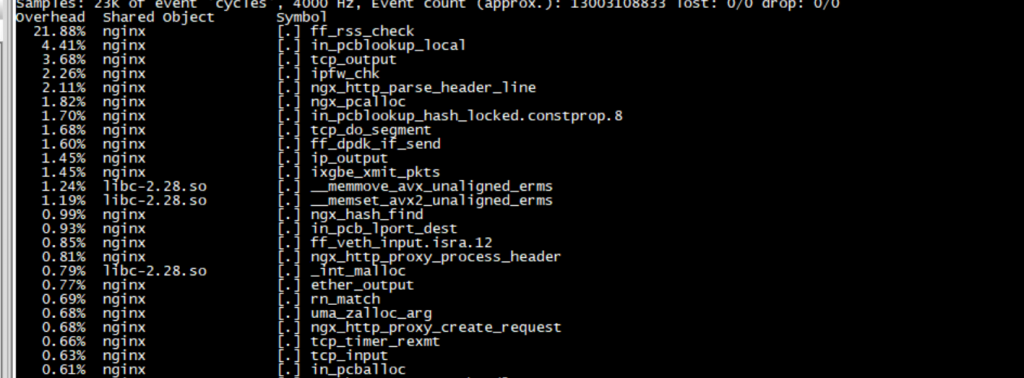
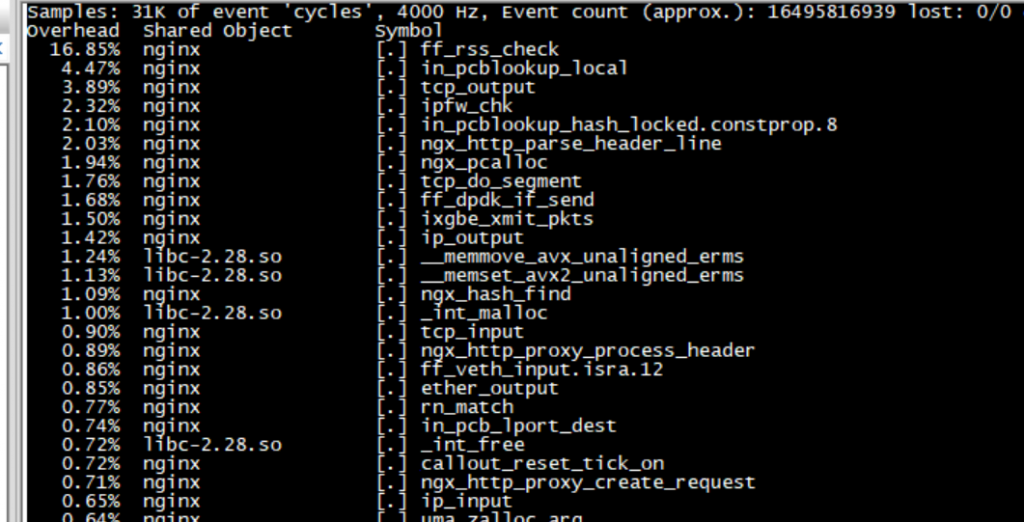
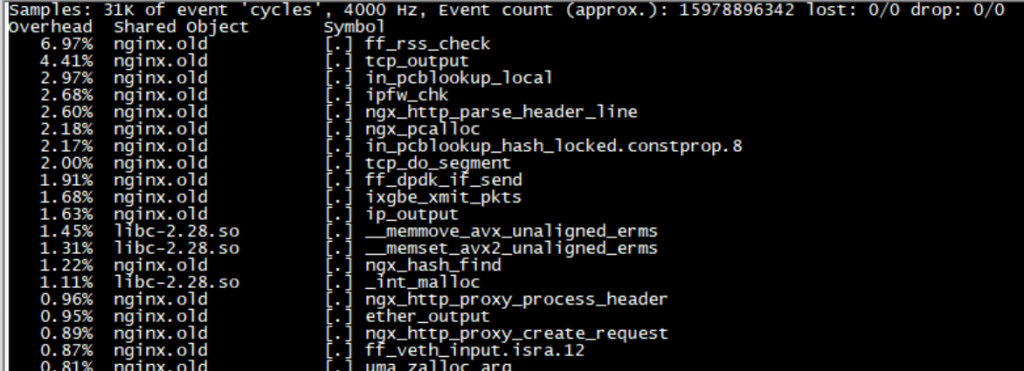
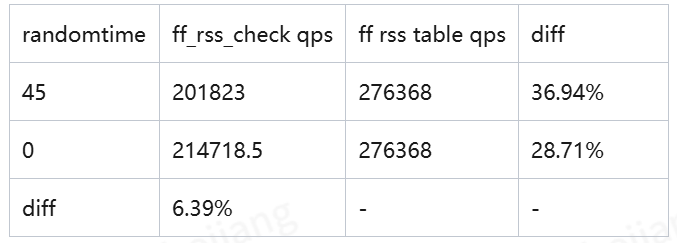
整理自 GitHub F-Stack/f-stack 仓库 issue 及 DPDK 官方文档
涉及 issue:#1035、#837、#693、#663、#583、#581、#531、#386、#379 等
最后更新:2026-03-09
一、问题概述
在运行 F-Stack(helloworld、nginx、自定义应用等)时,常见以下报错:
EAL: Error - exiting with code: 1
Cause: No probed ethernet devices
或:
ff_init failed with error "No probed ethernet devices"
该错误的根本原因是 DPDK 无法检测到可用的以太网设备,即 rte_eth_dev_count_avail() 返回 0。
这是 F-Stack 社区中出现频率最高的问题之一,历史上超过 10 个相关 issue,跨越 2019~2025 年,具有高度重复性。
二、根因分类
“No probed ethernet devices” 错误通常由以下几类原因导致,需按顺序逐一排查。
原因 1:网卡未绑定到 DPDK 兼容驱动
最常见原因。 DPDK 需要网卡从内核驱动(如 ixgbe、virtio)解绑,并重新绑定到 DPDK 专用驱动(igb_uio 或 vfio-pci)。
诊断命令:
cd /data/f-stack/dpdk
python3 usertools/dpdk-devbind.py --status
如果网卡显示在 Network devices using kernel driver 而不是 Network devices using DPDK-compatible driver,则需要绑定驱动。
解决方案:使用 igb_uio 绑定
# 1. 加载 igb_uio 模块
modprobe uio
insmod /data/f-stack/dpdk/build/kernel/linux/igb_uio/igb_uio.ko
2. 查看网卡 PCI 地址
python3 usertools/dpdk-devbind.py --status
3. 绑定网卡(替换 0000:00:03.0 为你的 PCI 地址)
python3 usertools/dpdk-devbind.py --bind=igb_uio 0000:00:03.0
4. 验证绑定成功
python3 usertools/dpdk-devbind.py --status
应看到网卡出现在 "Network devices using DPDK-compatible driver" 下
解决方案:使用 vfio-pci 绑定(推荐用于现代系统/虚拟机)
# 1. 加载 vfio-pci 模块
modprobe vfio-pci
2. 绑定网卡
python3 usertools/dpdk-devbind.py --bind=vfio-pci 0000:00:03.0
3. 如需在非 IOMMU 环境使用
echo 1 > /sys/module/vfio/parameters/enable_unsafe_noiommu_mode
原因 2:config.ini 中 port_list 未正确配置
config.ini 的 [dpdk] 段中必须配置 port_list,且其编号要与实际绑定的 DPDK 端口对应。
错误示例:
[dpdk]
port_list=0
配置了 port 0,但网卡未绑定或 PCI 白名单不匹配。
排查方法:
# 查看当前绑定的 DPDK 端口
python3 usertools/dpdk-devbind.py --status
运行 testpmd 验证 DPDK 可以看到设备
dpdk-testpmd -l 0-1 -n 4 -- -i
解决方案:
确认 pci_whitelist(旧版)或 allow(新版)参数与实际网卡 PCI 地址匹配:
[dpdk]
lcore_mask=1
channel=4
port_list=0
旧版 DPDK
pci_whitelist=0000:00:03.0
新版 DPDK (21.11+)
allow=0000:00:03.0
原因 3:Makefile 链接参数缺少 --whole-archive
在自定义应用中链接 F-Stack 时,如果没有使用 --whole-archive 标志,DPDK 的 NIC PMD(Poll Mode Driver)驱动库不会被完整链接进来,导致运行时找不到网卡。
错误写法(不完整):
LIBS += -lfstack -ldpdk
正确写法:
DPDK 19.11 及以下:
LIBS += -L${FF_PATH}/lib -Wl,--whole-archive,-lfstack,--no-whole-archive
LIBS += -L${FF_DPDK}/lib -Wl,--whole-archive,-ldpdk,--no-whole-archive
DPDK 20.11 / 21.11 及以上(使用 pkg-config):
CFLAGS += $(shell pkg-config --cflags libdpdk)
LDFLAGS += $(shell pkg-config --libs libdpdk)
LDFLAGS += -Wl,--whole-archive,-lfstack,--no-whole-archive
参考 f-stack/example/Makefile 作为标准模板
原因 4:pkg-config 版本过低
pkg-config 版本低于 0.28 时,无法正确解析 DPDK 的 .pc 文件,导致驱动库链接不完整,运行时检测不到网卡。
诊断命令:
pkg-config --version
解决方案:升级 pkg-config 到 0.28+
cd /data
wget https://pkg-config.freedesktop.org/releases/pkg-config-0.29.2.tar.gz
tar xzvf pkg-config-0.29.2.tar.gz
cd pkg-config-0.29.2
./configure --with-internal-glib
make && make install
mv /usr/bin/pkg-config /usr/bin/pkg-config.bak
ln -s /usr/local/bin/pkg-config /usr/bin/pkg-config
验证版本
pkg-config --version # 应显示 0.29.2
原因 5:Mellanox(MLX5)网卡缺少 glue 库
使用 Mellanox ConnectX 系列网卡时,DPDK 的 MLX5 PMD 需要额外的动态链接库支持。
错误日志:
net_mlx5: cannot load glue library: librte_pmd_mlx5_glue.so.xx.xx.x:
cannot open shared object file: No such file or directory
net_mlx5: cannot initialize PMD due to missing run-time dependency
on rdma-core libraries (libibverbs, libmlx5)
解决方案:
# 1. 安装 rdma-core 依赖
apt-get install rdma-core libibverbs-dev libmlx5-1 # Ubuntu
yum install rdma-core libibverbs libmlx5 # CentOS
2. 复制 glue 库到系统路径
cp /data/f-stack/dpdk/build/lib/librte_pmd_mlx5_glue.so.* /lib64/
ldconfig
3. 编译 DPDK 时启用 MLX5 支持
cd /data/f-stack/dpdk
make config T=x86_64-native-linuxapp-gcc
sed 's/CONFIG_RTE_LIBRTE_MLX5_PMD=n/CONFIG_RTE_LIBRTE_MLX5_PMD=y/g' \
-i build/.config
make clean && make && make install
4. 修改 config.ini 指定 PCI 地址
[dpdk]
pci_whitelist=0000:03:00.0
原因 6:在虚拟机中运行 / 无物理网卡
在笔记本、虚拟机或容器中没有 DPDK 兼容物理网卡时,需使用虚拟设备(vdev)。
使用 net_ring(内存环回设备):
[dpdk]
lcore_mask=1
channel=4
vdev=net_ring0
port_list=0
[port0]
addr=10.0.0.2
netmask=255.255.255.0
broadcast=10.0.0.255
gateway=10.0.0.1
注意: net_ring 仅用于测试/开发,不适用于生产环境。
在虚拟机中修复 igb_uio:
虚拟机中 pci_intx_mask_supported() 可能返回 false,需修改内核模块代码:
// 文件:f-stack/dpdk/kernel/linux/igb_uio/igb_uio.c 第 274 行
// 修改前:
if (pci_intx_mask_supported(udev->pdev)) {
// 修改后:
if (true || pci_intx_mask_supported(udev->pdev)) {
修改后重新编译 DPDK:
cd /data/f-stack/dpdk
meson -Denable_kmods=true build
ninja -C build && ninja -C build install
原因 7:使用 DPDK 共享库(.so)时驱动未加载
当使用 DPDK 动态库(CONFIG_RTE_BUILD_SHARED_LIB=y)时,PMD 驱动不会自动加载。
解决方案:
- 切换到 dev 分支代码(已修复此问题)
- 或改用静态库链接方式
原因 8:Rust binding 链接问题
在 Rust 项目中使用 F-Stack 绑定时,需要在构建脚本中明确链接 NIC 驱动库:
// build.rs
println!("cargo:rustc-link-lib=fstack");
println!("cargo:rustc-link-lib=rte_net_bond"); // 需要显式添加驱动库
// 使用 pkg-config 链接 DPDK
pkg_config::Config::new()
.print_system_libs(false)
.probe("libdpdk")
.unwrap();
注意: 确保 pkg-config 版本 ≥ 0.28,否则驱动库无法被正确识别。
三、快速排查流程
遇到 “No probed ethernet devices” 时,按以下步骤逐一排查:
Step 1: 检查网卡是否绑定 DPDK 驱动
└─ dpdk-devbind.py --status
├─ 未绑定 → 绑定 igb_uio 或 vfio-pci(见原因1)
└─ 已绑定 → 继续 Step 2
Step 2: 检查 config.ini 的 pci_whitelist/allow 是否正确
└─ 与 PCI 地址不匹配 → 修正 config.ini(见原因2)
└─ 匹配 → 继续 Step 3
Step 3: 检查是否自定义 Makefile / 应用
└─ 自定义 → 检查 --whole-archive 链接参数(见原因3)
└─ 使用示例 → 继续 Step 4
Step 4: 检查 pkg-config 版本
└─ < 0.28 → 升级 pkg-config(见原因4)
└─ ≥ 0.28 → 继续 Step 5
Step 5: 检查网卡类型
├─ Mellanox → 安装 rdma-core / 复制 glue 库(见原因5)
├─ 无物理网卡/虚拟机 → 使用 vdev 或修复 igb_uio(见原因6)
└─ 其他 → 确认网卡在 DPDK 支持列表中
四、验证步骤
修复后,按以下步骤验证:
# 1. 验证网卡绑定状态
python3 /data/f-stack/dpdk/usertools/dpdk-devbind.py --status
2. 用 testpmd 验证 DPDK 可以检测到设备
dpdk-testpmd -l 0-1 -n 4 -a 0000:00:03.0 -- -i
若看到 "Found 1 port(s)" 则正常
3. 运行 helloworld 验证 F-Stack 正常启动
cd /data/f-stack/example
./helloworld --conf /etc/f-stack.conf --proc-type=primary --proc-id=0
正常应显示 port 初始化信息,不出现 "No probed ethernet devices"
五、相关 issue 汇总
| Issue |
状态 |
关键场景 |
解决方案 |
| #1035 |
Open |
使用 vdev=net_ring0 但无效 |
检查 vdev 配置格式 |
| #837 |
Open |
阿里云服务器,eth0 仍使用内核驱动 |
绑定网卡到 DPDK 驱动 |
| #693 |
Open |
自定义应用中 ff_init 失败 |
Makefile 添加 –whole-archive |
| #663 |
Open |
Rust binding 运行失败 |
显式链接 PMD 驱动库 |
| #583 |
Closed |
使用 DPDK .so 动态库 |
切换到 dev 分支 |
| #581 |
Closed |
helloworld 运行失败 |
升级 pkg-config ≥ 0.28 |
| #531 |
Closed |
Mellanox MLX5 网卡 |
复制 glue 库到 /lib64 |
| #386 |
Closed |
ixgbe 网卡,驱动未绑定 |
绑定 igb_uio 驱动 |
| #379 |
Closed |
自定义 PMD 驱动未链接 |
在 Makefile 中链接 .a 文件 |
六、参考资料
*本文档由 OpenClaw 自动整理,基于 F-Stack GitHub issue 历史数据和 DPDK 官方文档。*